
- 분류 전체보기 (151)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- 알고풀자
- JWT
- Jinja2
- 스마일게이트
- 미니프로젝트
- R
- Ajax
- 마인크래프트뮤지컬
- 파이썬서버
- 카렌
- 스터디
- 프메
- EnhancedInput
- Unseen
- 언리얼
- Enhanced Input System
- node
- Bootstrap4
- 프린세스메이커
- Express
- 데이터베이스
- 디자드
- 게임개발
- 레베카
- VUE
- 정글사관학교
- flask
- 언리얼뮤지컬
- 으
- 언리얼프로그래머
- Today
- Total
Showing
PyTorch와 torchvision으로 MNIST 데이터셋 다루기 본문
오늘은 PyTorch를 사용하여 MNIST 데이터셋을 기반으로 완전 연결 신경망(fully-connected neural network)을 학습하는 방법에 대해 알아본다. MNIST 데이터셋은 손으로 쓴 숫자 이미지로 구성되어 있어 머신러닝 및 딥러닝 학습에 자주 사용되는 데이터셋이다.
우선 PyTorch와 torchvision을 사용하여 MNIST 데이터셋을 로드하고 다양한 방식으로 데이터를 시각화하고 배치 처리하도록 한다.
1. 필요한 라이브러리 설치 및 임포트하기
먼저, torchvision 라이브러리를 설치해야 한다. 이를 위해 아래의 명령어를 사용한다.
그 후, 필요한 라이브러리를 임포트한다.
import torch
import torchvision
MNIST 데이터셋을 다운로드
dataset = torchvision.datasets.MNIST('./', download=True)
데이터 타입들도 한번씩 확인해준다.
PyTorch를 사용하여 로드한 MNIST 데이터셋의 특정 이미지를 시각화
!pip install matplotlibmatplotlib.pyplot는 데이터 시각화를 위한 라이브러리로, 이미지를 화면에 표시하는 데 사용된다.
import matplotlib.pyplot as plt
%matplotlib inline
plt.title(target)
plt.imshow(data, cmap='gray')
data.show()target은 해당 이미지의 라벨(즉, 숫자)을 나타낸다. 이를 제목으로 설정하여 어떤 숫자인지를 알 수 있도록 한다.
- data는 MNIST 데이터셋의 이미지 데이터를 나타낸다. 이를 회색조(cmap='gray')로 표시한다.
- plt.imshow() 함수는 이미지를 시각화하는 역할을 한다.
- data.show()는 PIL 이미지 객체의 메서드로, 이미지를 별도의 창으로 표시하는 역할을 한다. 하지만 plt.imshow()와 함께 사용될 경우 중복이므로 일반적으로는 하나만 사용하면 된다.

2. 데이터 변환 설정하기
이미지를 텐서로 변환하기 위한 설정을 한다.
이를 위해 transforms.ToTensor()를 사용하여 데이터를 텐서로 변환하는 변환을 정의한다.
MNIST 데이터셋을 로드하고, 이미지 데이터를 처리한 후 첫 번째 이미지를 시각화하는 과정을 통해 딥러닝 모델을 학습하기 전에 데이터를 시각화하여 확인해볼 수 있다.
1. 데이터 변환 설정:
torchvision.transforms에서 제공하는 변환을 사용하여 이미지를 텐서로 변환하는 ToTensor를 정의한다. ToTensor는 이미지의 픽셀 값을 [0, 1] 범위로 정규화하여 PyTorch 텐서로 변환한다.
import torchvision.transforms as transforms
# batch must contain tensors, numpy arrays, numbers, dicts or lists
ToTensor = transforms.Compose([
transforms.ToTensor()
])2. MNIST 데이터셋 로드:
dataset = torchvision.datasets.MNIST('./', transform = ToTensor)- MNIST 데이터셋을 다운로드하여 로드하고, 방금 정의한 ToTensor 변환을 적용한다. 이 데이터셋은 손으로 쓴 숫자 이미지와 해당 라벨로 구성되어 있다.
3. 데이터 로더 생성:
data_loader = torch.utils.data.DataLoader(dataset,
batch_size=1,
shuffle=True)데이터셋을 배치로 나누고 셔플하여 데이터 로더를 생성한다. 여기서는 배치 크기를 1로 설정하여 한 번에 하나의 이미지만 로드한다.
여기서, 배치 크기가 1로 설정된다면 한 번에 하나의 이미지만 처리하고, 만약 배치 크기가 10으로 설정된다면 여러 이미지를 로드하게 된다.
4. PIL 이미지 변환 설정:
텐서를 PIL 이미지로 변환하기 위한 변환 ToPILImage를 정의한다. 이 변환을 통해 텐서 데이터를 다시 이미지 형태로 변환할 수 있다.
ToPILImage = transforms.Compose([
transforms.ToPILImage()
])
MNIST 데이터의 형태
- 데이터 형태:
- MNIST 데이터셋의 이미지는 28x28 픽셀로 구성되어 있다.
- PyTorch에서는 데이터를 텐서 형태로 다루는데, 일반적으로 이미지는 (배치 크기, 채널 수, 높이, 너비)의 형태를 가진다.
- MNIST 이미지의 경우는 회색조 이미지이기 때문에 채널 수가 1이다. 따라서, 하나의 MNIST 이미지의 형태는 (1, 28, 28)이 된다.
- 여기서:
- 1은 채널 수 (회색조이므로 1)
- 28은 높이 (세로 픽셀 수)
- 28은 너비 (가로 픽셀 수)
- 여기서:
5. 데이터 로드 및 시각화:
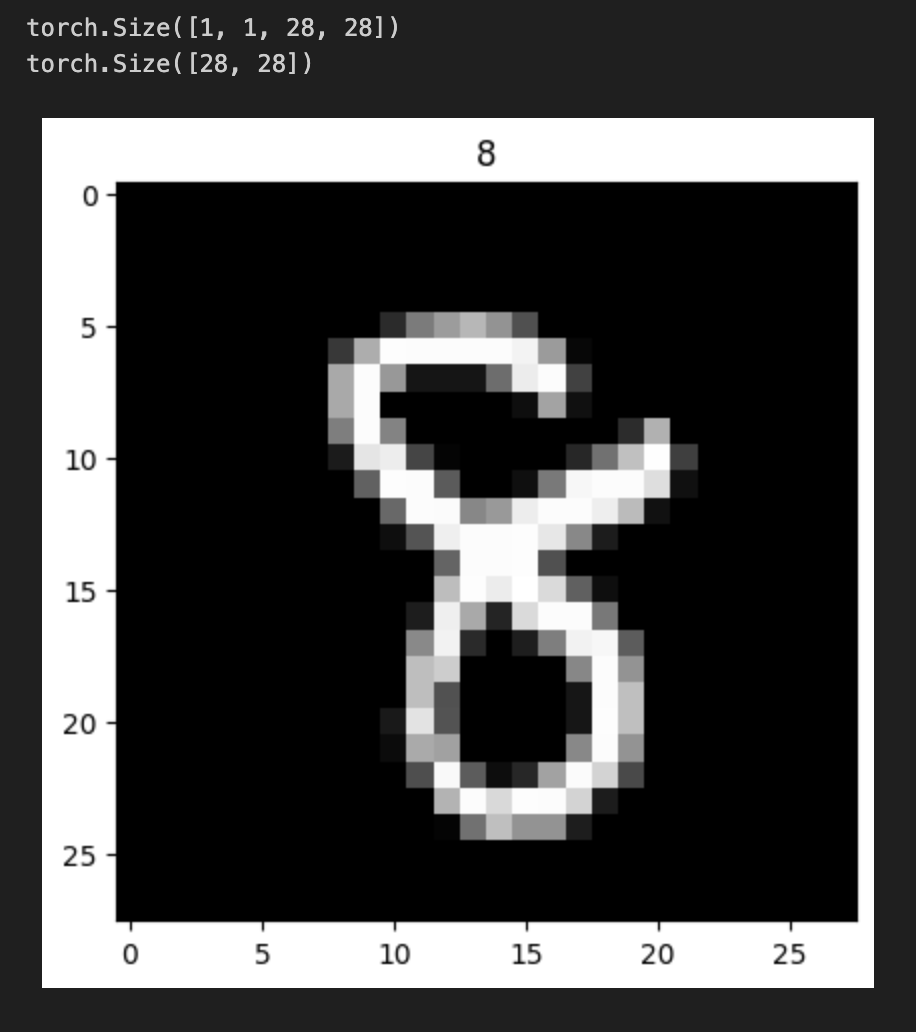
for data, target in data_loader:
print(data.shape) # 데이터의 형태 출력
data = data.squeeze() # 불필요한 차원 하나를 줄인다 (배치 크기)
data = data.squeeze() # 불필요한 차원 하나를 줄인다 (채널)
print(data.shape) # 수정된 데이터 형태 출력
pic = ToPILImage(data) # 텐서를 PIL 이미지로 변환
plt.title(int(target)) # 라벨을 제목으로 설정
plt.imshow(pic, cmap='gray') # 이미지를 회색조로 표시
plt.show() # 이미지를 화면에 표시
break # 첫 번째 이미지만 표시하고 루프 종료
- data_loader에서 데이터를 가져와서 반복문을 실행한다. 각 배치에서 data는 이미지 데이터이고, target은 해당 라벨이다.
- print(data.shape)를 통해 원본 데이터의 형태를 출력한다. MNIST 이미지의 경우 보통 (1, 28, 28) 형태를 가지며, 여기서 1은 채널 수를 나타낸다.
- data.squeeze()를 두 번 호출하여 불필요한 차원을 제거한다. 첫 번째 호출로 배치 차원(1)을 제거하고, 두 번째 호출로 채널 차원(1)도 제거하여 최종적으로 (28, 28) 형태로 만든다.
- 수정된 데이터 형태를 출력한 후, ToPILImage 변환을 사용하여 텐서를 PIL 이미지로 변환한다.
- 마지막으로, 이미지를 시각화하여 해당 라벨을 제목으로 설정하고, plt.imshow()로 이미지를 표시한 후 plt.show()로 출력한다. break를 사용하여 루프를 종료하므로 첫 번째 이미지만 시각화된다.
data.squeeze() 메서드의 역할
- data.squeeze():
- squeeze() 메서드는 텐서의 차원 중 크기가 1인 차원을 제거하는 함수이다.
- data의 초기 형태가 (1, 28, 28)일 때, data.squeeze()를 한 번 호출하면 첫 번째 차원인 1이 제거되어 (28, 28) 형태가 된다.
- 이 상태에서 다시 squeeze()를 호출하면 더 이상 제거할 차원이 없으므로, 데이터의 형태는 그대로 (28, 28)로 유지된다.
- 예를 들어, 다음과 같은 과정이 있다:
- 초기 데이터 형태: (1, 28, 28) (배치 크기와 채널 수 포함)
- 첫 번째 squeeze() 호출 후: (28, 28) (배치 차원 제거)
- 두 번째 squeeze() 호출 후: 여전히 (28, 28) (채널 차원도 제거)
결국, 이미지를 시각화하기 위해 차원을 조정하는 과정이 필요한데, 시각화하려면 이미지의 형태가 (28, 28) 여야 하므로, 불필요한 차원을 제거하는 것이다.
배치사이즈가 1이 아니라 10이라면...
data_loader = torch.utils.data.DataLoader(dataset,
batch_size=10,
shuffle=True)
ToPILImage = transforms.Compose([
transforms.ToPILImage()
])
for data, target in data_loader:
index = 5
print(data.shape)
img = data[index]
print(img.shape)
img = img[0]
print(img.shape)
pic = ToPILImage(img)
plt.title(int(target[index]))
plt.imshow(img, cmap='gray')
plt.show()
break
배치테스트 코드
# 1000개 batch
n = 1000
data_loader = torch.utils.data.DataLoader(dataset,
batch_size=n,
shuffle=True)
i = 0
l = []
for data, target in data_loader:
i += len(data)
l.append(len(data))
print(l)
print('Total number of data: {}'.format(i))
# 2000개 batch
n = 2000
data_loader = torch.utils.data.DataLoader(dataset,
batch_size=n,
shuffle=True)
i = 0
l = []
for data, target in data_loader:
i += len(data)
l.append(len(data))
print(l)
print('Total number of data: {}'.format(i))
# 999개 batch
n = 999
data_loader = torch.utils.data.DataLoader(dataset,
batch_size=n,
shuffle=True)
i = 0
l = []
for data, target in data_loader:
i += len(data)
l.append(len(data))
print(l)
print('Total number of data: {}'.format(i))출력 결과
[1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000]
Total number of data: 60000
[2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000, 2000]
Total number of data: 60000
[999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 999, 60]
Total number of data: 60000각 배치에서 데이터와 타겟을 가져오고, i에 현재 배치의 데이터 수를 더하여 총 데이터 수를 계산한다. 또한, 각 배치의 크기를 리스트 l에 추가한다. 마지막으로, 각 배치의 크기와 전체 데이터 수를 출력한다.
요약
- MNIST 데이터셋을 다양한 배치 크기(1000, 2000, 999)로 로드하고, 각 배치의 크기와 전체 데이터 수를 출력하는 기능을 한다.
- 이를 통해 배치 크기에 따라 데이터 로딩의 유연성을 실험하고, 각 배치에서 얼마나 많은 데이터가 로드되는지를 확인할 수 있다.
출력 결과 예시
- 각 배치의 크기를 출력한 후, 마지막에 "Total number of data: ..." 문구로 전체 데이터 수를 출력한다. MNIST 데이터셋의 경우 60,000개의 훈련 데이터가 있기 때문에 총 데이터 수는 60,000으로 나올 것이다. 각 배치 크기 설정에 따라 실제 출력은 다를 수 있지만, 모든 데이터가 사용되었음을 확인할 수 있다.
'컴퓨터 공학, 전산학 > 인공지능,딥러닝' 카테고리의 다른 글
| LSE, Least Squares Estimation(최소 제곱 추정) (0) | 2024.10.15 |
|---|---|
| 정규 분포의 확률 밀도 함수(PDF, Probability Density Function) (0) | 2024.10.15 |
| sklearn의 load_digits 데이터 분석과 classification 학습 (0) | 2024.10.06 |
| M1 맥에서 import torch 하기 (4) | 2024.10.04 |
| 역전파(backpropagation) (1) | 2024.10.04 |


