
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 스트림릿
- VUE
- nixos한글설정\
- 블랙스크린복구
- 으
- JWT
- Jinja2
- flask
- 지우개신공 #pc자기진단 #ram미인식 #컴퓨터고장해결 #램인식불량 #pc자가수리 #컴퓨터고장해결 #조립pc
- 프메
- pandas
- 판다스
- streamlit
- 오픈소스
- 알고풀자
- 파이썬서버
- 미니프로젝트
- Enhanced Input System
- inxos
- 정글사관학교
- Express
- 언리얼뮤지컬
- ossca
- Bootstrap4
- 마인크래프트뮤지컬
- nixos한글키보드
- 메모리인식불량
- 디자드
- EnhancedInput
- R
- Today
- Total
Today, I will
sklearn의 load_digits 데이터 분석과 classification 학습 본문
sklearn의 load_digits 데이터 분석과 classification 학습
Lv.Forest 2024. 10. 6. 16:58이번 포스트에서는 sklearn 라이브러리에서 제공하는 load_digits 데이터를 사용하여 기본적인 데이터 분석과 분류 모델을 학습하는 과정을 살펴본다. load_digits 데이터는 손으로 쓴 숫자 이미지를 8x8 크기의 행렬로 표현한 것으로, 각 숫자는 0에서 9까지의 값을 갖는다. 이를 통해 숫자를 분류하는 머신러닝 모델을 만들어본다.
from sklearn import tree
from sklearn import datasets
import pandas as pd
import seaborn as sns
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline1. 데이터 로드 및 구조 확인
data = datasets.load_digits()먼저, datasets.load_digits()를 사용해 데이터를 불러온다.
print(data.keys())
for f in data.keys():
t = type(data[f])
print('key: {}, type: {}'.format(f, t))
if t == np.ndarray:
print('shape: {}'.format(data[f].shape))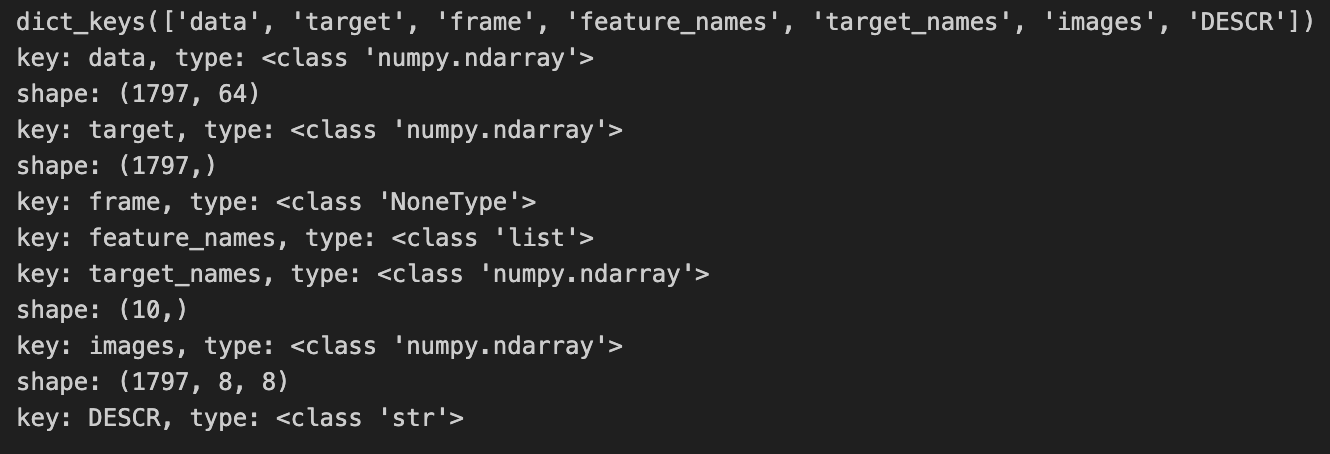
데이터를 불러오면, data, target, images, DESCR 등의 키로 구성된 딕셔너리 형태로 제공된다.
각 키의 내용을 확인하면, data는 숫자 이미지의 픽셀 값을 담고 있으며, target은 각 숫자의 레이블을 나타낸다.
print(data.DESCR)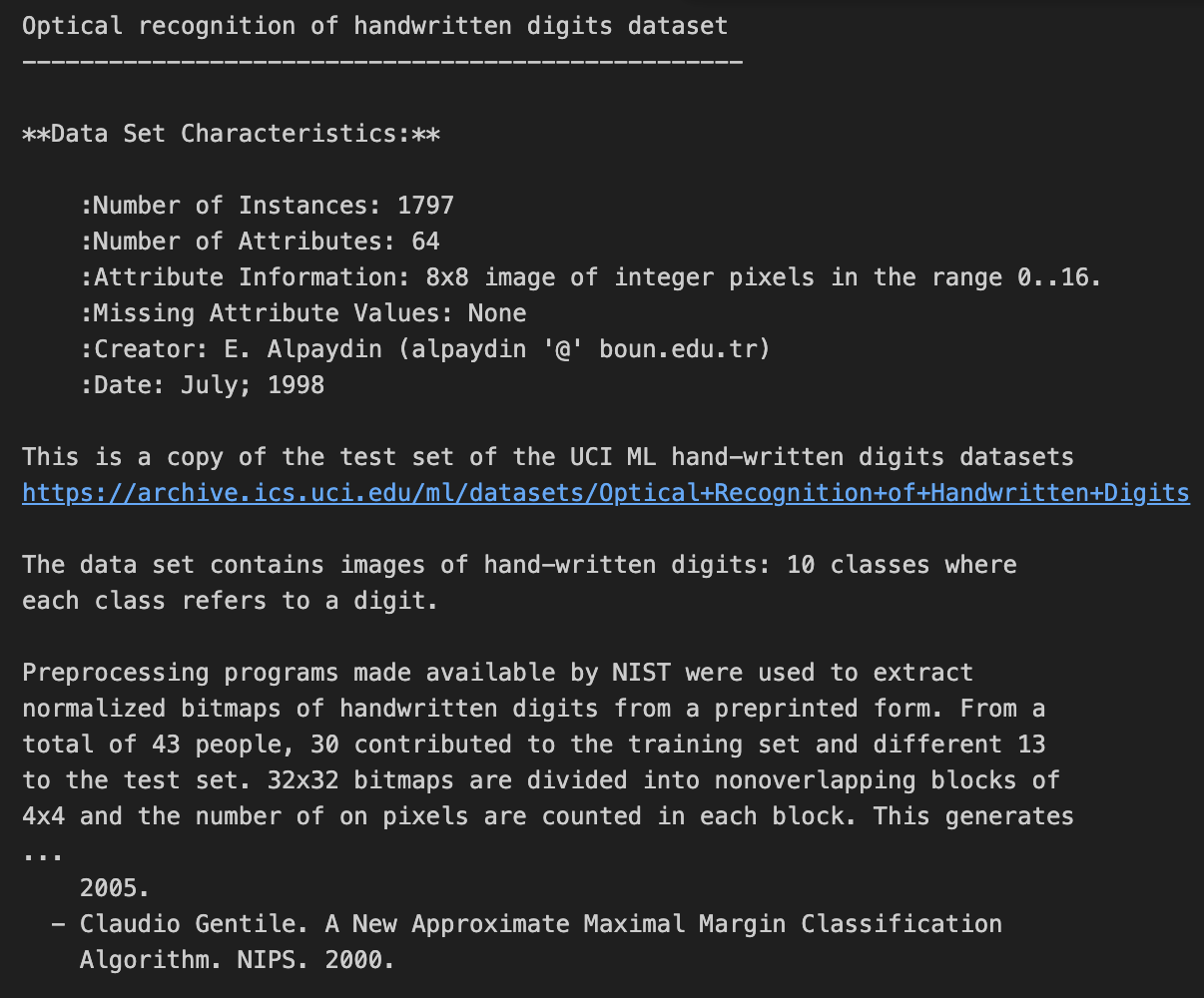
손으로 쓴 숫자 데이터 세트의 광학 인식
--------------------------------------------------
**데이터 세트 특성:**
:인스턴스 수: 1797
:속성 수: 64
:속성 정보: 0..16 범위의 정수 픽셀로 구성된 8x8 이미지
:누락된 속성 값: 없음
:작성자: E. 알페이딘(알페이딘 '@' boun.edu.tr)
:Date: 7월; 1998
다음은 UCI ML 손으로 쓴 숫자 데이터 세트의 테스트 세트 사본입니다.
https://archive.ics.uci.edu/ml/datasets/Optical+손글씨+숫자+인식+데이터세트
이 데이터 세트에는 손으로 쓴 숫자의 이미지가 포함되어 있습니다: 10개의 클래스
각 클래스는 숫자를 나타냅니다.
NIST에서 제공하는 전처리 프로그램을 사용하여
미리 인쇄된 손글씨 이미지에서 손으로 쓴 숫자의 정규화된 비트맵을 추출하는 데 사용되었습니다.
총 43명 중 30명이 훈련 세트에, 나머지 13명이 테스트 세트에 제공했습니다.
32x32 비트맵은 겹치지 않는 블록으로 나뉩니다.
4x4의 블록으로 나뉘고 각 블록에서 온 픽셀의 수를 계산합니다.
2. 데이터프레임으로 변환 및 기초 통계 분석
이제 데이터를 판다스의 DataFrame으로 변환하고, 데이터의 기초 통계를 확인해본다.
df = pd.DataFrame(data=data.data)
df['target'] = data.target
print(data.target_names)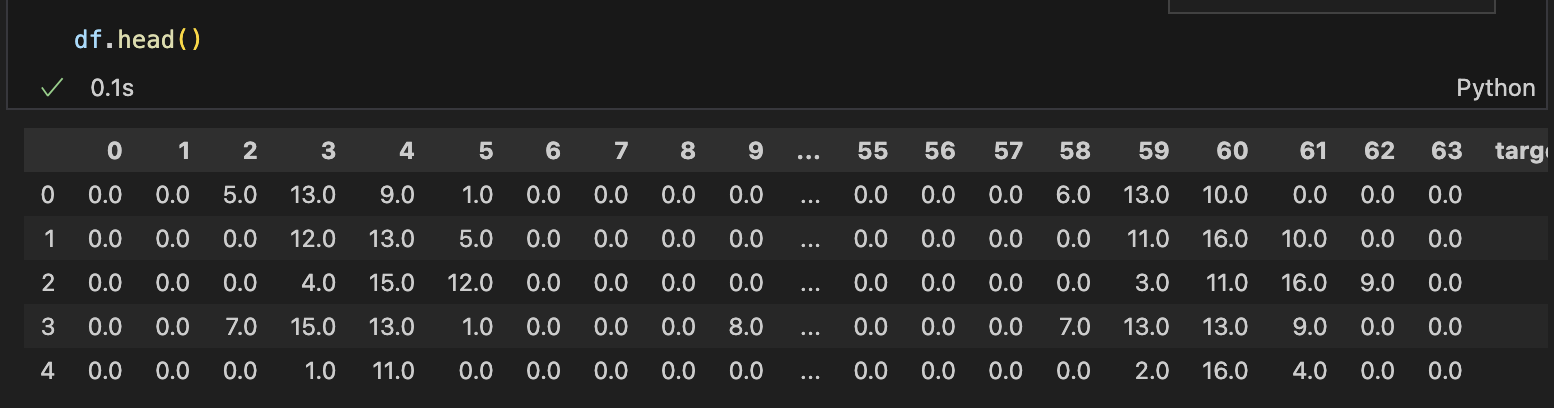
데이터프레임의 구조를 확인한 뒤, 각 열에 대한 통계 정보를 얻기 위해 describe() 함수를 사용한다.
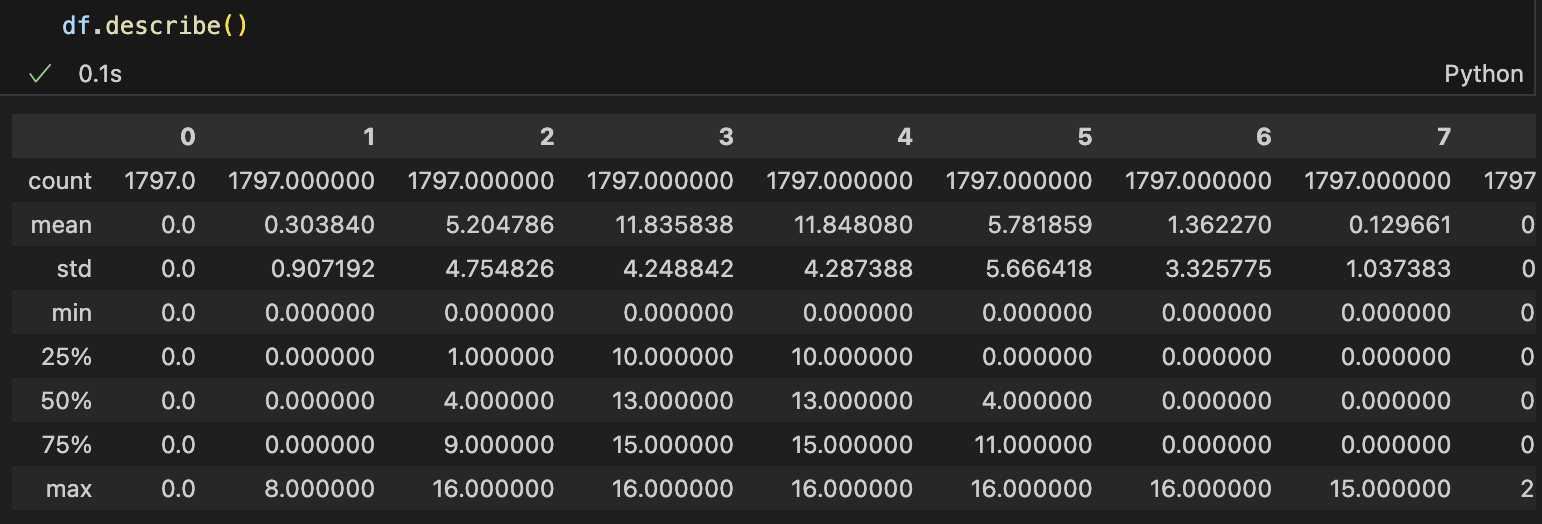
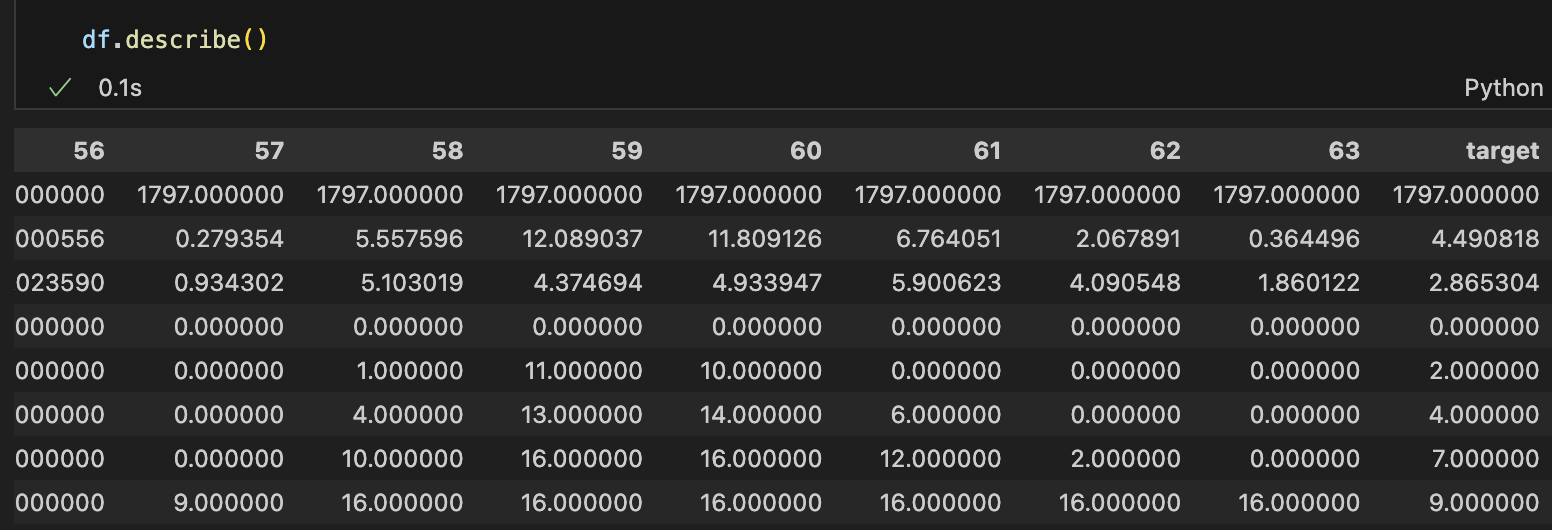
8 rows × 65 columns
df.info()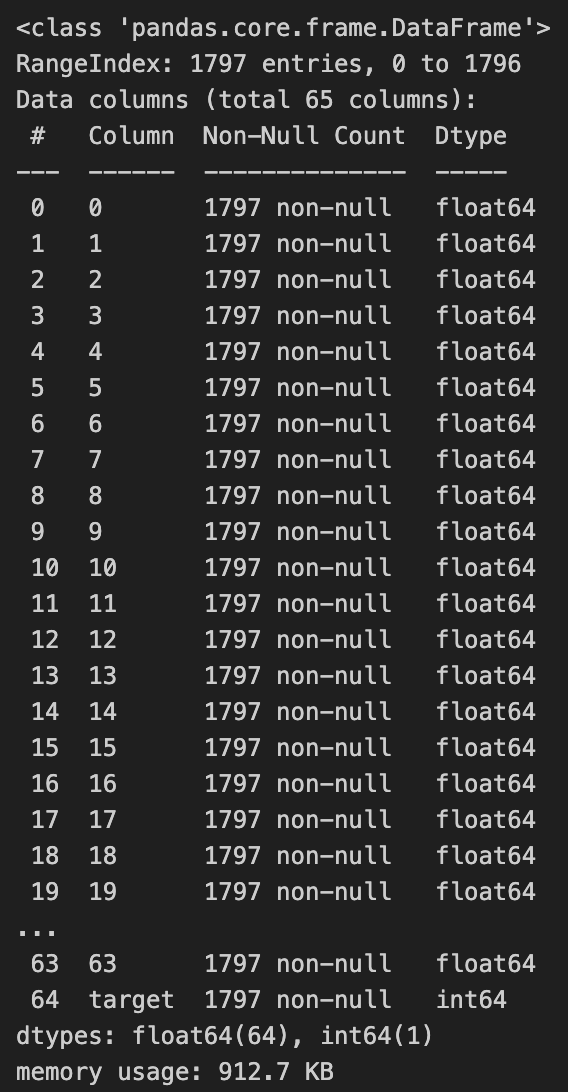
print(df.isnull().sum())
df.plot()
3. 데이터 시각화
데이터셋에 포함된 숫자 이미지를 시각화하여 확인할 수 있다. 아래 코드는 100번째 데이터의 이미지를 그레이스케일로 출력한다.
import matplotlib.pyplot as plt
plt.imshow(data.data[100].reshape(8, 8).astype(np.int32), cmap='gray')이 코드를 통해 숫자 이미지가 어떻게 구성되어 있는지 시각적으로 확인할 수 있다.
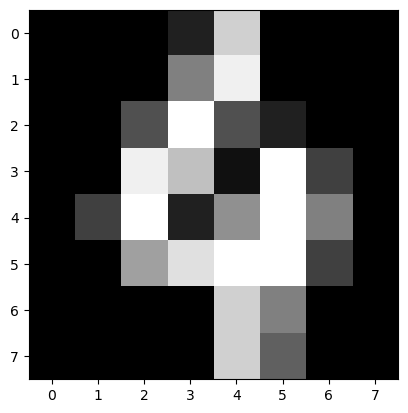
4. 결정 트리 모델을 이용한 분류 학습
이제 DecisionTreeClassifier를 사용하여 손글씨 숫자 분류 모델을 학습시킨다.
모델 학습을 위해 fit() 메소드를 사용하며, 학습 데이터 전체를 학습시키는 방식으로 진행한다.
X_train = data.data
y_train = data.targetmodel = tree.DecisionTreeClassifier()model.fit(X_train, y_train)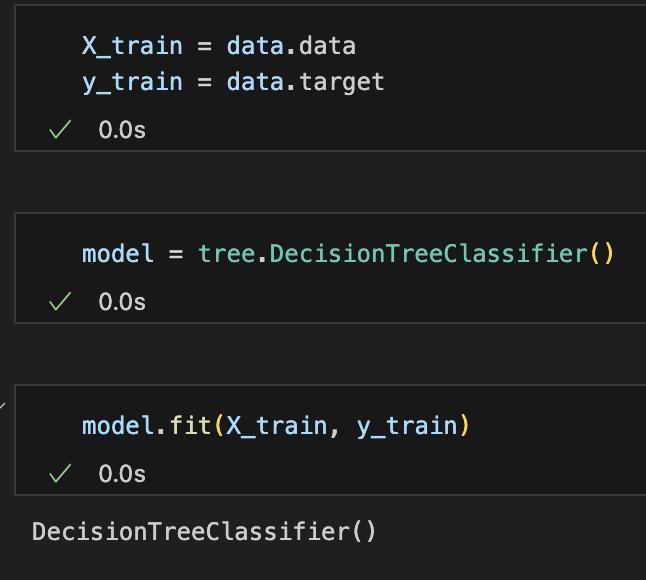
y = model.predict(X_train)import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import axes3d, Axes3D
fig, axs = plt.subplots(ncols=2, figsize=(10, 5), subplot_kw={"projection":"3d"})
for ax, data in zip(axs, [y, y_train]):
ax.scatter(X_train[:,0], X_train[:,1],X_train[:,2], c=data)
plt.show()print(model.score(X_train, y_train))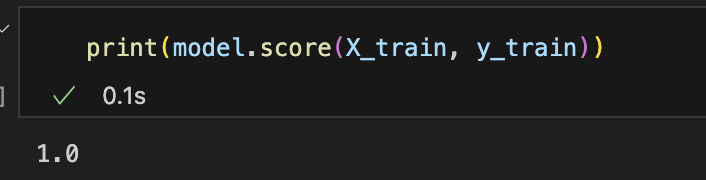
모델을 학습한 후에는 score() 메소드를 사용하여 학습 데이터에 대한 정확도를 확인할 수 있다.
모델이 예측한 확률을 확인하고 싶다면, predict_proba() 메소드를 사용하여 특정 데이터의 클래스 확률을 출력할 수 있다.
( 모델이 특정 데이터에 대해 각 클래스에 속할 확률을 예측하는 과정을 보여준다.)
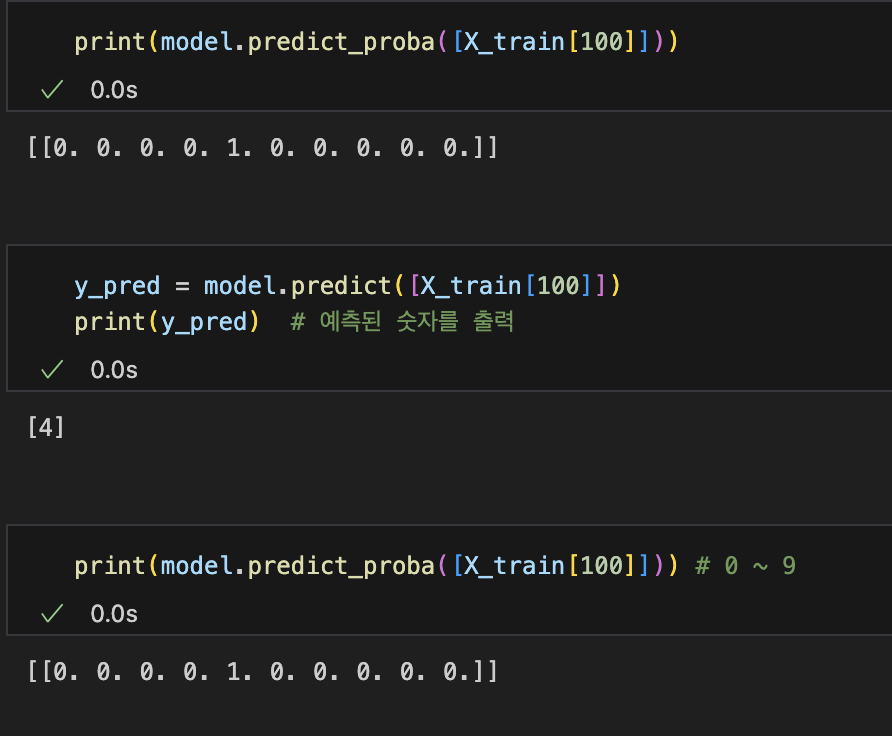
print(model.predict_proba([X_train[100]]))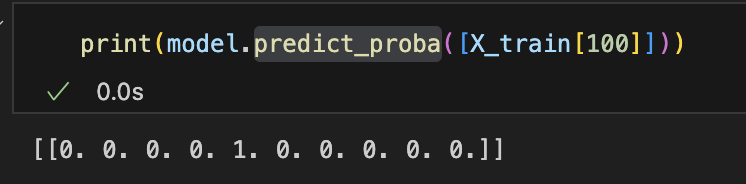
- model.predict_proba([X_train[100]])는 학습된 DecisionTreeClassifier 모델이 100번째 학습 데이터에 대해 예측하는 각 클래스(숫자 0~9)의 확률 분포를 반환한다.
- 예측된 결과 [[0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]]는 확률 분포를 나타낸다. 여기서 각 숫자(0~9)에 대해 해당 데이터가 그 숫자일 확률을 계산한 것이다.
- 100번째 데이터가 숫자 3일 확률이 1.0로 나타나 있다. 즉, 모델은 이 데이터가 숫자 3일 것이라고 확신하고 있다는 의미다.
- 다른 확률 값들이 모두 0인 이유는, DecisionTreeClassifier 모델은 결정 트리 기반으로 예측하기 때문에 각 데이터 포인트에 대해 매우 결정적인 (확정적인) 예측을 내린다.
이 함수는 특히 확률 기반 평가가 필요할 때 유용하며, 단순히 어떤 클래스에 속하는지(predict)뿐만 아니라, 그 클래스에 속할 확률을 알고 싶을 때 사용된다.
5. 3D 시각화
마지막으로, 학습한 모델의 예측 결과를 3D 그래프로 시각화할 수 있다. 이를 통해 데이터의 분포와 예측된 클래스가 어떻게 다른지 확인해본다.
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import axes3d, Axes3D
fig, axs = plt.subplots(ncols=2, figsize=(10, 5), subplot_kw={"projection":"3d"})
for ax, data in zip(axs, [y, y_train]):
ax.scatter(X_train[:,0], X_train[:,1],X_train[:,2], c=data)
plt.show()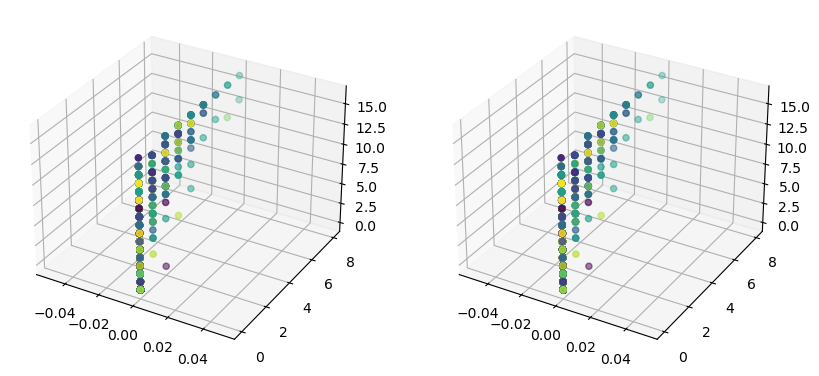
ax.scatter(X_train[:,0], X_train[:,1], X_train[:,2], c=data)
- X_train[:,0]: 학습 데이터 X_train의 첫 번째 열(0번째 열)을 가져와서 x축 좌표로 사용한다. 이 열은 각 데이터 포인트의 첫 번째 특성(feature) 값을 의미한다.
- X_train[:,1]: X_train의 두 번째 열(1번째 열)을 가져와서 y축 좌표로 사용한다. 각 데이터 포인트의 두 번째 특성 값을 나타낸다.
- X_train[:,2]: X_train의 세 번째 열(2번째 열)을 가져와서 z축 좌표로 사용한다. 즉, 각 데이터 포인트의 세 번째 특성 값이다.
이 세 가지 특성 값들을 x, y, z 좌표로 사용해서 3D 공간에 점을 찍는다.
c=data
- c=data: 이 부분은 각 점의 색상을 결정한다. data는 타겟 값(숫자 0~9)을 의미하며, 그 값에 따라 점들의 색깔이 달라진다.
- 예를 들어, y_train이 사용되면, 각 데이터 포인트가 실제로 어떤 숫자(0~9)에 속하는지에 따라 다른 색깔로 표시된다.
즉, 이 코드는 3D 그래프에 각 데이터 포인트를 찍으면서, 각 점의 색깔을 그 점이 실제로 어떤 숫자인지에 따라 다르게 보여준다. 이걸 통해 3차원 공간에서 데이터가 어떻게 분포되어 있는지, 그리고 다른 숫자들이 어떤 패턴을 보이는지 시각적으로 확인할 수 있다.
그래프 설명: 그래프는 학습 데이터의 일부 열을 x, y, z 축으로 하여 3D로 표시하고 있다.왼쪽과 오른쪽의 그래프는 동일한 3차원 데이터를 시각화하지만, 색상에 따라 표시된 데이터가 다를 수 있다. 예를 들어, 하나는 y 예측값에 따른 색상이고, 다른 하나는 실제 타겟 값인 y_train에 따른 색상. 요약: 이 코드는 학습 데이터(X_train)의 첫 세 가지 특성(피처)을 3차원 좌표계에서 시각화한 것이다. 각 데이터 포인트는 y와 y_train에 따라 다른 색으로 표시되어 있어 모델이 예측한 결과와 실제 값의 차이를 시각적으로 확인할 수 있게 돕는다.
for ax, data in zip(axs, [y, y_train]):
ax.scatter(X_train[:,0], X_train[:,1],X_train[:,2], c=data)
왼쪽 그래프: y 값을 사용해서 색상을 지정. 즉, 모델이 예측한 값이 기준이 되는 그래프.
학습된 모델이 X_train 데이터를 보고 예측한 값들이 y에 저장되어 있고, 그 값을 기반으로 점들의 색이 결정
오른쪽 그래프: y_train 값을 사용해서 색상을 지정해. 실제 타겟 값(정답)을 기준으로 함.
y_train은 원래 데이터에 있는 정답(숫자 0~9)을 나타내고, 그 값에 따라 각 점의 색깔이 다르게 표시됨.
정리:
- 왼쪽: 모델이 예측한 값에 따른 색상 (모델의 결과)
- 오른쪽: 실제 정답 값에 따른 색상 (실제 데이터)
이걸 통해, 모델이 예측한 결과와 실제 정답 간의 차이를 시각적으로 비교할 수 있게 된다.
만약 두 그래프가 비슷하게 보인다면, 그 모델의 예측 성능이 좋다는 의미이다.
결론
이번 포스트에서는 load_digits 데이터를 활용해 데이터 분석과 분류 모델 학습을 수행해보았다. 결정 트리 모델을 사용해 손글씨 숫자를 분류하였으며, sklearn의 데이터 로드 및 데이터 시각화 및 학습 성능을 확인하였다.
학습을 마친 모델에 새로운 데이터를 넣으면, 그 데이터가 어떤 클래스로 분류되었는지 예측할 수 있다.
1. 학습(Training)
먼저, `DecisionTreeClassifier()` 같은 분류 모델을 학습 데이터(`X_train`, `y_train`)로 학습한다. 이 학습 과정에서 모델은 **특성(feature)**과 타겟 값(label) 간의 관계를 학습하게 된다.
model = tree.DecisionTreeClassifier()
model.fit(X_train, y_train)
여기서 `X_train`은 입력 데이터(손글씨 숫자의 픽셀값 배열)이며, `y_train`은 그에 해당하는 실제 정답(숫자 0~9)이다.
2. 예측(Prediction)
모델이 학습을 마치면, 이제 새로운 데이터에 대해 예측할 수 있다. 예를 들어, 학습 데이터 중 하나를 다시 모델에 넣어 모델이 어떻게 분류하는지 확인해본다.
y_pred = model.predict([X_train[100]])
print(y_pred) # 예측된 숫자를 출력
여기서 `model.predict()`는 새로운 데이터가 들어왔을 때 그것이 어떤 숫자(클래스)인지 예측한다. 만약 `X_train[100]`을 넣으면, 모델은 이 데이터가 숫자 '4'일 것이라고 예측할 수 있다.
3. 예측 확률 확인
`predict_proba()` 함수는 각 클래스(0~9)에 속할 확률을 보여준다. 이 확률을 보면, 모델이 해당 데이터를 어떤 숫자로 분류했는지 더 명확히 알 수 있다.
print(model.predict_proba([X_train[100]]))
이 결과는 예를 들어, 다음과 같이 나올 수 있다:
[[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]]
이 값은 각 클래스(숫자 0~9)에 속할 확률을 의미한다. 여기서는 1.0이 3번째 자리에 있으므로, 모델은 이 데이터를 숫자 3으로 분류한 것이다.
4. 분류(클래스 예측 결과) 시각화
이제 학습된 모델이 데이터를 어떻게 분류했는지 3D 그래프로 확인할 수 있다. `y`는 모델이 예측한 결과이며, `y_train`은 실제 정답이다. 두 그래프를 비교하여 모델이 얼마나 정확하게 분류했는지 알 수 있다.
fig, axs = plt.subplots(ncols=2, figsize=(10, 5), subplot_kw={"projection":"3d"})
for ax, data in zip(axs, [y, y_train]):
ax.scatter(X_train[:,0], X_train[:,1], X_train[:,2], c=data)
plt.show()
- 왼쪽 그래프: 모델이 예측한 값을 기반으로 색을 칠한 것이다.
- 오른쪽 그래프: 실제 정답 값을 기반으로 색을 칠한 것이다.
두 그래프가 비슷하다면 모델이 데이터를 정확하게 분류했음을 시각적으로 확인할 수 있다.
학습된 모델은 새로운 데이터를 입력하면 그 데이터를 어떤 숫자(클래스)로 분류할지 예측해준다. `predict()` 함수로 예측된 클래스 값을 확인할 수 있으며, `predict_proba()` 함수로 각 클래스에 속할 확률도 확인할 수 있다. 3D 시각화를 통해 모델의 예측 결과와 실제 정답 값을 비교할 수 있다. 모델을 학습한 후, 새로운 데이터가 들어오면 자동으로 분류(클래스 예측)된 결과를 알 수 있다.
'Computer Science > 인공지능,딥러닝' 카테고리의 다른 글
| 정규 분포의 확률 밀도 함수(PDF, Probability Density Function) (0) | 2024.10.15 |
|---|---|
| PyTorch와 torchvision으로 MNIST 데이터셋 다루기 (2) | 2024.10.10 |
| M1 맥에서 import torch 하기 (4) | 2024.10.04 |
| 역전파(backpropagation) (1) | 2024.10.04 |
| 캐글에서 데이터를 가져오기 (1) | 2024.09.30 |

