| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Unseen
- Enhanced Input System
- 카렌
- 미니프로젝트
- 레베카
- 언리얼
- 디자드
- node
- 파이썬서버
- 알고풀자
- Ajax
- 게임개발
- VUE
- flask
- 언리얼뮤지컬
- Jinja2
- 마인크래프트뮤지컬
- JWT
- 프메
- 데이터베이스
- 으
- 언리얼프로그래머
- R
- EnhancedInput
- Express
- 스터디
- 스마일게이트
- 정글사관학교
- Bootstrap4
- 프린세스메이커
- Today
- Total
Today, I will
[자료구조, 파이썬] Linked list의 특징과 구현, 시간복잡도, 리트코드 문제풀이 본문
[자료구조, 파이썬] Linked list의 특징과 구현, 시간복잡도, 리트코드 문제풀이
Lv.Forest 2023. 5. 20. 15:37* 이론을 토대로 직접 구현한 것이므로 버그가 발생할 수 있습니다. 버그 발생시 댓글 남겨주시면 감사하겠습니다.

1. 물리적 비연속적, 논리적 연속적
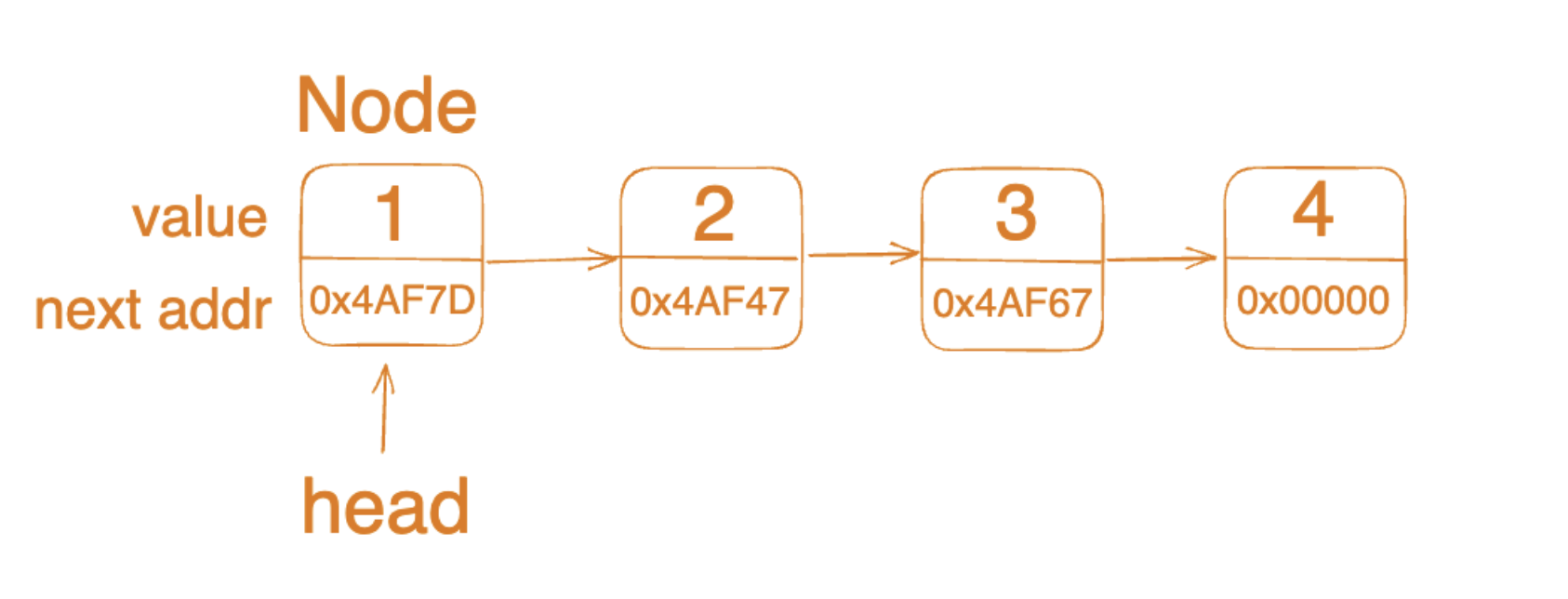
Linked List는 Node라는 구조체가 연결되는 형식으로 데이터를 저장하는 자료구조입니다. 각각의 요소(Node)가 데이터 값과 다음 요소를 가리키는 포인터(next node의 주소값)로 구성된 자료구조입니다.
각 Node들은 데이터를 저장할 뿐 아니라, next node의 addr 정보도 가지고 있기 때문에 논리적으로 연속성을 유지하면서 연결될 수 있습니다. Array의 경우 연속성을 유지하기 위해 메모리 상에서 순차적으로 데이터를 저장하는 방식을 사용하였지만, Linked lsit에는 메모리상에서 연속성을 유지하지 않아도 되기 때문에 메모리 사용이 좀 더 자유롭습니다. 다만 next node의 addr도 추가적으로 저장해야 하기 때문에 데이터 하나당 차지하는 메모리가 더 커지게 됩니다.
- 장점 : 새로운 요소의 삽입과 삭제가 다른 요소들을 이동시키지 않아도 가능합니다. 단지 링크를 조정하면 되기 때문에 비교적 빠른 성능을 보입니다.
- 단점 : 임의의 위치에 접근하기 위해서는 처음부터 순차적으로 탐색해야 하기 때문에 접근 시간이 오래 걸립니다.
- 데이터의 삽입과 삭제가 빈번하게 일어나는 경우, 데이터의 순서가 자주 변경되는 경우에 적합합니다.
따라서, Array List는 인덱스를 사용한 임의의 접근과 데이터의 삽입/삭제가 적은 상황에 유리하며, Linked List는 데이터의 순서 변경과 삽입/삭제가 빈번한 상황에 유리합니다.
- 싱글 링크드 리스트(단순 연결 리스트) 연산들의 시간 복잡도
(1) 탐색 시간 복잡도
- 가장 앞 노드부터 다음 노드를 하나씩 보면서 원하는 데이터를 갖는 데이터를 찾습니다.
- 링크드 리스트안에 찾는 데이터가 없거나 또는 찾으려는 데이터가 마지막 노드에 있는 최악의 경우 n개의 노드를 다 봐야합니다.
- 최악의 경우 시간 복잡도 : O(n)
(2) 삽입 / 삭제 시간 복잡도
- 삽입, 삭제는 주변 노드들에 연결된 레퍼런스만 수정합니다.
- 그러므로 시간은 특정 값에 비례하지 않고 항상 일정합니다.
- 시간 복잡도 : O(1)
(3) 현실적인 삽입 / 삭제 시간 복잡도
- head와 tail노드를 제외한 나머지 노드들은 탐색이나 접근 연산을 통해서 가지고 와야 합니다.
- 현실적인 삽입/삭제 시간 복잡도 = 원하는 노드에 접근/탐색 + 삽입/삭제 = O(n)
(4) 삽입/삭제 연산 특수 경우 시간 복잡도
- head와 tail노드와 관련있는 삽입이나 삭제연산들은 시간복잡도가 O(1)입니다.
| 연산 | 시간 복잡도 |
| 접근 | O(n) |
| 탐색 | O(n) |
| 삽입 | O(1) |
| 삭제 | O(1) |
| 원하는 노드에 접근/탐색 + 삽입 | O(n) |
| 원하는 노드에 접근/탐색 + 삭제 | O(n) |
| 가장 앞에 삽입 | O(1) |
| 가장 앞에 삭제 | O(1) |
| 가장 뒤에 삽입/삭제 | tail이 있다면O(1), tail이 없다면 O(n) |
2. 연결리스트 구현 (파이썬)
(1) 노드의 생성
링크드리스트는 노드로 이루어져있습니다. 이 노드는 어떻게 구현하느냐에 따라서, 링크드리스트가 될 수도 있고 트리가 될 수도 있고 그래프가 될 수도 있습니다.
class Node:
def __init__(self, value = 0, next = None):
self.value = value
self.next = next클래스로 노드를 구현하면 위와 같이 노드를 생성할 때, value값과 next 값을 초기화해줍니다. (어떤 값도 들어오지 않을 경우 value는 0, next는 None 값)
(2) 노드의 사용
class Node:
def __init__(self, value = 0, next = None):
self.value = value
self.next = next
first = Node(1) #Node의 값이 1이고 이 노드를 first가 가리킨다
second = Node(2)
third = Node(3)
first.next = second
second.next = third
first.value = 6(3) 링크드리스트 구현
우선 링크드리스트 클래스에 head값이 있어야 합니다. head가 링크드리스트의 첫번째 노드를 가리킴으로써, 어느 인덱스든 접근할 수 있도록 하기 위함입니다.
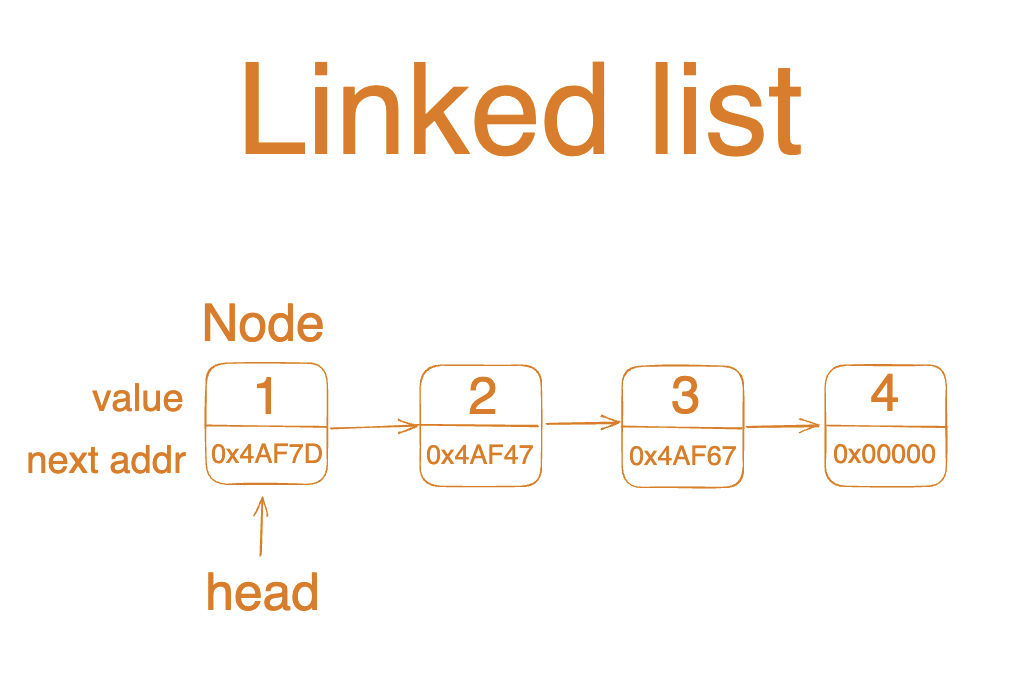
링크드리스트 생성자를 호출하면 head는 none 값을 가리키게끔 세팅해줍니다.

class LinkedList(object):
def __init__(self):
self.head = None
def append(self, value):
pass
def get(self, idx):
pass
def insert(self, idx, value):
pass
def delete(self, idx):
pass
li = LinkedList()<1> append(insert_back) 구현 - no tail version
실행부
li = LinkedList()
li.append(1)
li.append(2)
li.append(3)
li.append(4)로직 + 실행부
class Node:
def __init__(self, value = 0, next = None):
self.value = value
self.next = next
class LinkedList(object):
def __init__(self):
self.head = None
def append(self, value):
new_node = Node(value)
if self.head is None:
self.head = new_node
else:
current = self.head
while(current.next):
current = current.next
current.next = new_node
li = LinkedList()
li.append(1)
li.append(2)
li.append(3)
li.append(4)<1> append(insert_back) 구현 - tail version
tail 로직으로 링크드리스트 append를 구현하면 시간복잡도 O(1)에 맞출 수 있습니다. tail로 인하여 추가하고자 하는 인덱스로 바로 접근할 수 있기 때문입니다. tail node의 next로 삽입할 new_node 지정해주고, tail이 new_node를 가리키게 작성해주면 됩니다.
class Node:
def __init__(self, value = 0, next = None):
self.value = value
self.next = next
class LinkedList(object):
def __init__(self):
self.head = None
self.tail = None
def append(self, value):
new_node = Node(value)
if self.head is None:
self.head = new_node
self.tail = new_node
else:
self.tail.next = new_node
self.tail = new_node
li = LinkedList()
li.append(1)
li.append(2)
li.append(3)
li.append(4)
cur_node = li.head
while(1):
print(cur_node.value)
cur_node = cur_node.next
if cur_node == li.tail:
print(cur_node.value)
break<2> get 구현 : 해당 인덱스의 값
1차 구현 : 원하는 인덱스까지 가려면 O(n)의 시간복잡도가 걸린다.
class Node:
def __init__(self, value = 0, next = None):
self.value = value
self.next = next
class Linked_list:
def __init__(self):
self.head = None
def append(self, value):
new_node = Node(value)
if self.head == None:
self.head = new_node
else:
cur_node = self.head
while(cur_node.next):
cur_node = cur_node.next
cur_node.next = new_node
def get(self, idx):
i = 0
cur_node = self.head
while(cur_node.next and i < idx):
cur_node = cur_node.next
i += 1
if i != idx:
print("None!")
else:
print(cur_node.value)
li = Linked_list()
li.append(1)
li.append(2)
li.append(3)
li.append(4)
li.append(5)
li.get(0)
li.get(1)
li.get(3)
li.get(6)2차 구현
def get(self, idx):
i = 0
cur_node = self.head
while(cur_node.next):
if i == idx:
print(cur_node.value)
return
else:
cur_node = cur_node.next
i += 1
print("None!")for문을 사용해본 구현
def get(self, idx):
i = 0
cur_node = self.head
for _ in range(idx):
if cur_node.next != None:
cur_node = cur_node.next
else:
print("None!")
return
print(cur_node.value)<3> insert_at 구현 : 중간 삽입
링크드 리스트의 중간 삽입과 중간 삭제 연산의 시간 복잡도는 다음과 같습니다:
(1) 삽입(Insertion) :
-1- 최선의 경우 (첫 번째 노드 앞에 삽입): O(1)
-2- 평균 및 최악의 경우 (중간 또는 tail 없는 상태에서 마지막에 삽입): O(n)
(2) 삭제 (Deletion):
-1- 최선의 경우 (첫 번째 노드 삭제): O(1)
-2- 평균 및 최악의 경우 (중간 또는 마지막 노드 삭제): O(n)
링크드 리스트의 특성상 삽입 및 삭제 연산에는 노드의 위치를 탐색해야 하는 경우가 있습니다. 만약 특정 위치를 알고 있다면 삽입 및 삭제는 O(1)의 시간 복잡도를 가질 수 있습니다. 하지만 일반적으로는 특정 위치를 찾기 위해 순차적으로 노드를 탐색해야 하므로, 삽입 및 삭제 연산의 시간 복잡도는 O(n)입니다.
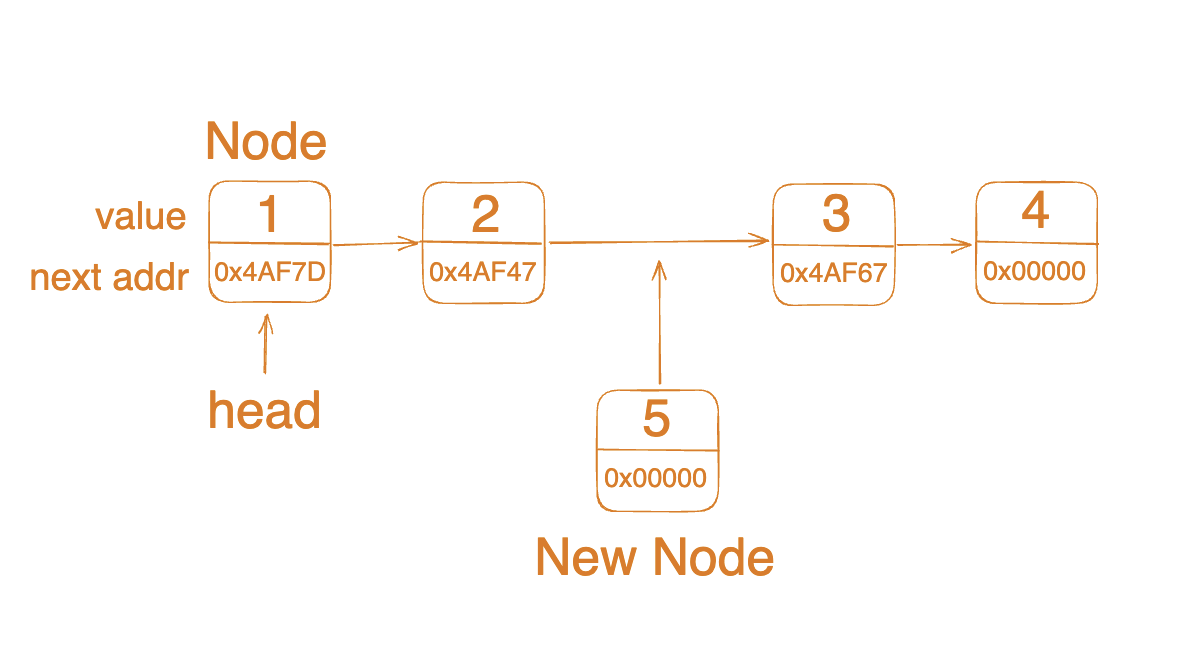
구현을 위해서는 임의의 인덱스에 new node가 들어가야 하므로 기존 연결관계를 변경해주어야 합니다.
삽입 노드의 next는 목표 인덱스에 있던 원래 노드로 설정해주고, 목표 인덱스 전에 있던 노드의 next를 삽입 노드로 바꾸어주어야 합니다.
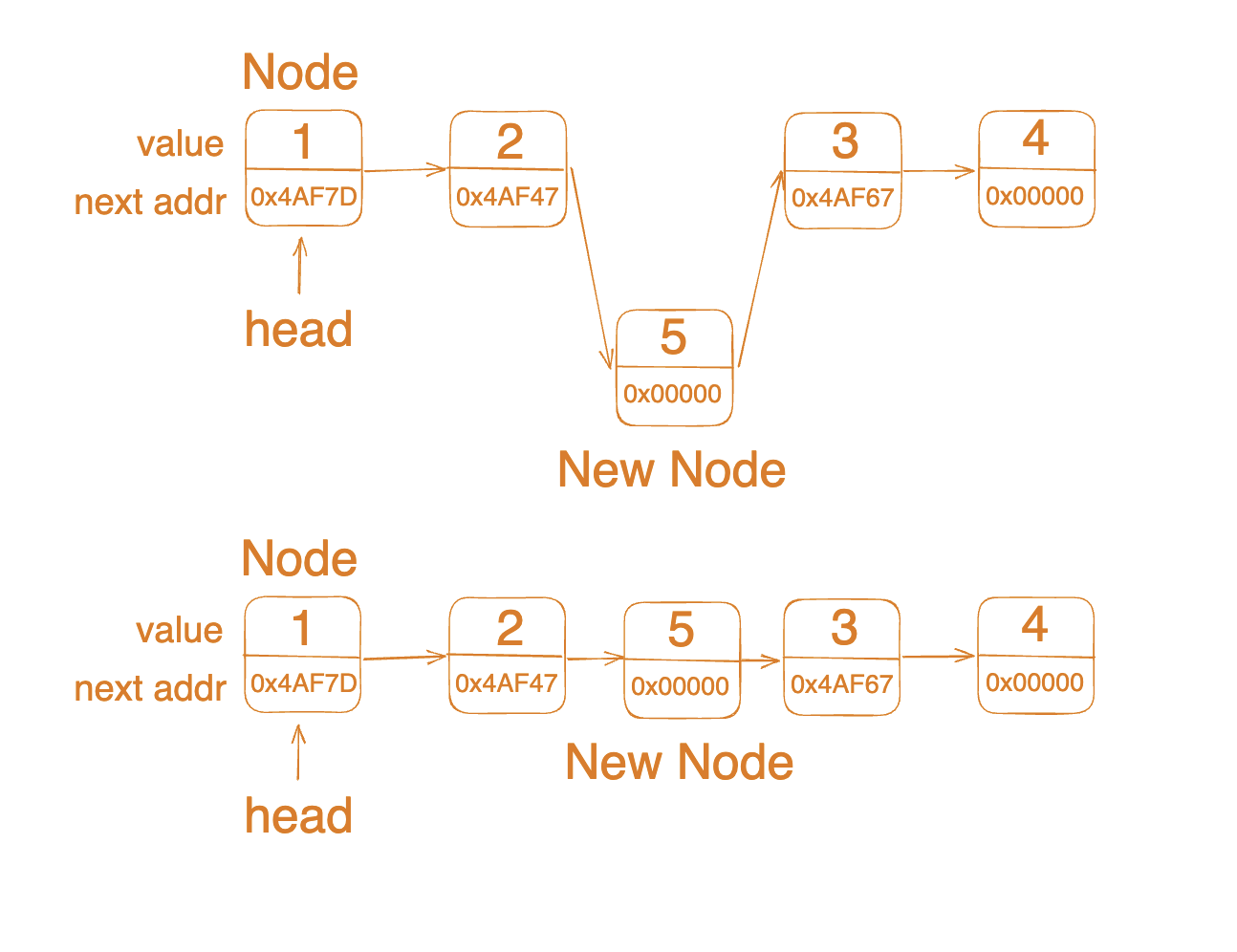
구현시에 주의할 점은 목표 인덱스의 전 노드까지만 탐색한 다음에 해당 노드의 next가 삽입 노드의 next가 될 수 있도록 하고, 기존 목표 인덱스의 전 노드의 next를 삽입 노드로 바꾸어주어야 한다는 것입니다. 이 순서가 바뀌어 버리면 삽입 노드의 이후 노트를 찾아갈 수 없게 되기 때문입니다.
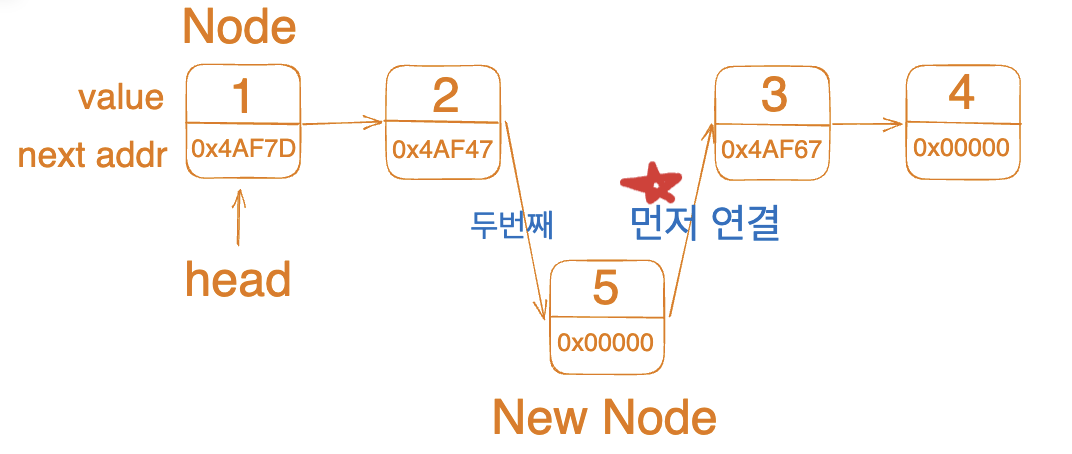
def insert_at(self, idx, value):
new_node = Node(value)
cur_node = self.head
if idx == 0:
new_node.next = self.head
self.head = new_node
return
for _ in range(idx-1):
if cur_node.next != None:
cur_node = cur_node.next
else:
print("out of index range!")
return
new_node.next = cur_node.next
cur_node.next = new_node중간 점검
class Node:
def __init__(self, value = 0, next = None):
self.value = value
self.next = next
class Linked_list:
def __init__(self):
self.head = None
def append(self, value):
new_node = Node(value)
if self.head == None:
self.head = new_node
else:
cur_node = self.head
while(cur_node.next):
cur_node = cur_node.next
cur_node.next = new_node
def get(self, idx):
i = 0
cur_node = self.head
for _ in range(idx):
if cur_node.next != None:
cur_node = cur_node.next
else:
print("None!")
return
print(idx,"인덱스의 값: ",cur_node.value)
def insert_at(self, idx, value):
new_node = Node(value)
cur_node = self.head
if idx == 0:
new_node.next = self.head
self.head = new_node
return
for _ in range(idx-1):
if cur_node.next != None:
cur_node = cur_node.next
else:
print("out of index range!")
return
new_node.next = cur_node.next
cur_node.next = new_node
li = Linked_list()
li.append(1)
li.append(2)
li.append(3)
li.append(4)
li.append(5)
# 1 2 3 4 5
li.get(0) # 1
li.get(1) # 2
li.get(3) # 4
li.get(6) # None!
li.insert_at(0, 7)
li.insert_at(2, 999)
li.insert_at(5, 0)
li.insert_at(100, 0) # out of index range!
# 7 1 999 2 3 0 4 5 None! None!
for i in range(10):
li.get(i)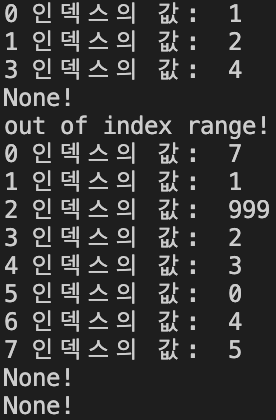
<4> remove_at 구현 : 중간 삭제
삭제 목표 인덱스의 앞 노드까지만 가서 해당 노드의 next를 다음 노드(삭제하고 싶은 노드)의 next로 바꿔주기만 하면 됩니다.
파이썬으로 구현 중이기 때문에 삭제 노드는 따로 free 처리해주지 않아도 해당 노드를 아무도 참조하고 있지 않다는 사실이 확인되면 가비지 컬렉터가 알아서 메모리에서 삭제해주기 때문입니다.
def remove_at(self, idx):
cur_node = self.head
if idx == 0:
self.head = cur_node.next
return
for _ in range(idx-1):
if cur_node.next:
cur_node = cur_node.next
else:
print("out of index range!")
return
cur_node.next = cur_node.next.next지금까지 전체 코드와 출력
class Node:
def __init__(self, value = 0, next = None):
self.value = value
self.next = next
class Linked_list:
def __init__(self):
self.head = None
def append(self, value):
new_node = Node(value)
if self.head == None:
self.head = new_node
else:
cur_node = self.head
while(cur_node.next):
cur_node = cur_node.next
cur_node.next = new_node
def get(self, idx):
i = 0
cur_node = self.head
for _ in range(idx):
if cur_node.next != None:
cur_node = cur_node.next
else:
print("None!")
return
print(idx,"인덱스의 값: ",cur_node.value)
def insert_at(self, idx, value):
new_node = Node(value)
cur_node = self.head
if idx == 0:
new_node.next = self.head
self.head = new_node
return
for _ in range(idx-1):
if cur_node.next != None:
cur_node = cur_node.next
else:
print("out of index range!")
return
new_node.next = cur_node.next
cur_node.next = new_node
def remove_at(self, idx):
cur_node = self.head
if idx == 0:
self.head = cur_node.next
return
for _ in range(idx-1):
if cur_node.next:
cur_node = cur_node.next
else:
print("out of index range!")
return
cur_node.next = cur_node.next.next
li = Linked_list()
li.append(1)
li.append(2)
li.append(3)
li.append(4)
li.append(5)
# 1 2 3 4 5
li.get(0) # 1
li.get(1) # 2
li.get(3) # 4
li.get(6) # None!
li.insert_at(0, 7)
li.insert_at(2, 999)
li.insert_at(5, 0)
li.insert_at(100, 0) # out of index range!
# 7 1 999 2 3 0 4 5 None! None!
for i in range(10):
li.get(i)
print("-------------------------")
li.remove_at(0)
li.remove_at(2)
li.remove_at(10) # out of index range!
# 1 999 3 0 4 5 None! None!
for i in range(10):
li.get(i)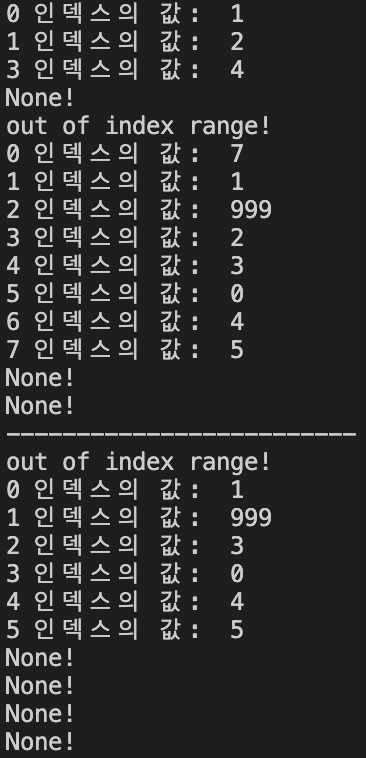
3. 리트코드 : 더블링크드리스트 풀이
https://leetcode.com/problems/design-browser-history/
Design Browser History - LeetCode
Can you solve this real interview question? Design Browser History - You have a browser of one tab where you start on the homepage and you can visit another url, get back in the history number of steps or move forward in the history number of steps. Implem
leetcode.com
You have a browser of one tab where you start on the homepage and you can visit another url, get back in the history number of steps or move forward in the history number of steps.
Implement the BrowserHistory class:
- BrowserHistory(string homepage) Initializes the object with the homepage of the browser.
- void visit(string url) Visits url from the current page. It clears up all the forward history.
- string back(int steps) Move steps back in history. If you can only return x steps in the history and steps > x, you will return only x steps. Return the current url after moving back in history at most steps.
- string forward(int steps) Move steps forward in history. If you can only forward x steps in the history and steps > x, you will forward only x steps. Return the current url after forwarding in history at most steps.
Constraints:
- 1 <= homepage.length <= 20
- 1 <= url.length <= 20
- 1 <= steps <= 100
- homepage and url consist of '.' or lower case English letters.
- At most 5000 calls will be made to visit, back, and forward.
더블링크드 리스트 풀이
class Node():
def __init__(self, homepage = 0, next = None, prev = None):
self.next = None
self.prev = None
self.homepage = homepage
class BrowserHistory(object):
def __init__(self, homepage):
self.head = Node(homepage)
self.cur = self.head
def visit(self, url): #append
new_node = Node(url)
self.cur.next = new_node
new_node.prev = self.cur
self.cur = new_node
def back(self, steps): #앞 인덱스
for i in range(steps):
if self.cur == self.head:
return self.cur.homepage
self.cur = self.cur.prev
return self.cur.homepage
def forward(self, steps): # 뒤 인덱스
for i in range(steps):
if self.cur.next == None:
return self.cur.homepage
self.cur = self.cur.next
return self.cur.homepage
back과 forward에서 break를 쓰는 것이 더 깔끔할지도..
class Node():
def __init__(self, homepage = 0, next = None, prev = None):
self.next = None
self.prev = None
self.homepage = homepage
class BrowserHistory(object):
def __init__(self, homepage):
self.head = Node(homepage)
self.cur = self.head
def visit(self, url): #append
new_node = Node(url)
self.cur.next = new_node
new_node.prev = self.cur
self.cur = new_node
def back(self, steps): #앞 인덱스
for i in range(steps):
if self.cur == self.head:
break
self.cur = self.cur.prev
return self.cur.homepage
def forward(self, steps): # 뒤 인덱스
for i in range(steps):
if self.cur.next == None:
break
self.cur = self.cur.next
return self.cur.homepage
'Computer Science > 자료구조' 카테고리의 다른 글
| [자료구조, 파이썬] Queue과 Stack의 개념과 구현 (0) | 2023.05.24 |
|---|---|
| [자료구조] Array list와 배열(Array) 개념과 장단점, 시간복잡도 (1) | 2023.05.19 |
| Sentinel node를 사용하여 구현한 레드블랙 트리(2) - 삭제로직 (0) | 2023.04.05 |
| Sentinel node를 사용하여 구현한 레드블랙 트리(1) - 삽입로직 (0) | 2023.04.05 |