| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Unseen
- 디자드
- 언리얼프로그래머
- 스마일게이트
- 게임개발
- 프린세스메이커
- node
- Bootstrap4
- 언리얼
- 레베카
- JWT
- 스터디
- Express
- 파이썬서버
- 알고풀자
- 정글사관학교
- 마인크래프트뮤지컬
- EnhancedInput
- 언리얼뮤지컬
- VUE
- Jinja2
- flask
- 데이터베이스
- R
- Ajax
- 미니프로젝트
- Enhanced Input System
- 으
- 카렌
- 프메
- Today
- Total
목록Computer Science/인공지능,딥러닝 (20)
Today, I will
 정규 분포의 확률 밀도 함수(PDF, Probability Density Function)
정규 분포의 확률 밀도 함수(PDF, Probability Density Function)
정규 분포의 확률 밀도 함수(PDF, Probability Density Function)는 통계학에서 아주 중요한 개념이다. 정규 분포는 주로 우리가 일상에서 관찰하는 많은 자연현상과 데이터가 '평균 주변에 많이 몰려 있고, 극단적으로 큰 값이나 작은 값은 적다'는 패턴을 따를 때 유용하다. 예를 들어, 사람들의 키, 시험 점수, 제품의 생산 품질 등이 이런 정규 분포를 따를 수 있다.1. 정규 분포란?정규 분포는 통계에서 데이터가 평균을 중심으로 대칭적으로 분포하는 형태를 말한다. 이를 시각적으로 보면 종 모양의 그래프를 떠올리면 된다. 가장 흔히 발생하는 값들이 가운데 집중되어 있고, 평균에서 멀어질수록 발생 빈도가 줄어드는 형태다.정규 분포는 두 가지 중요한 특성인 평균과 표준편차로 정의된다:평균..
 PyTorch와 torchvision으로 MNIST 데이터셋 다루기
PyTorch와 torchvision으로 MNIST 데이터셋 다루기
오늘은 PyTorch를 사용하여 MNIST 데이터셋을 기반으로 완전 연결 신경망(fully-connected neural network)을 학습하는 방법에 대해 알아본다. MNIST 데이터셋은 손으로 쓴 숫자 이미지로 구성되어 있어 머신러닝 및 딥러닝 학습에 자주 사용되는 데이터셋이다. 우선 PyTorch와 torchvision을 사용하여 MNIST 데이터셋을 로드하고 다양한 방식으로 데이터를 시각화하고 배치 처리하도록 한다. 1. 필요한 라이브러리 설치 및 임포트하기먼저, torchvision 라이브러리를 설치해야 한다. 이를 위해 아래의 명령어를 사용한다. !pip install torchvision 그 후, 필요한 라이브러리를 임포트한다. import torchimport torchvisionMNI..
 sklearn의 load_digits 데이터 분석과 classification 학습
sklearn의 load_digits 데이터 분석과 classification 학습
이번 포스트에서는 sklearn 라이브러리에서 제공하는 load_digits 데이터를 사용하여 기본적인 데이터 분석과 분류 모델을 학습하는 과정을 살펴본다. load_digits 데이터는 손으로 쓴 숫자 이미지를 8x8 크기의 행렬로 표현한 것으로, 각 숫자는 0에서 9까지의 값을 갖는다. 이를 통해 숫자를 분류하는 머신러닝 모델을 만들어본다.from sklearn import treefrom sklearn import datasetsimport pandas as pdimport seaborn as snsimport numpy as npfrom matplotlib import pyplot as plt%matplotlib inline1. 데이터 로드 및 구조 확인data = datasets.load_dig..
M1에서는 특정 명령어로 PyTorch를 설치pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu!pip3 install numpy matplotlibimport torchimport numpy as np 1. M1 칩의 아키텍처 특성:ARM 기반: M1 칩은 x86 기반의 Intel 칩과는 다른 ARM 아키텍처를 사용GPU 호환성: M1 칩에 내장된 GPU는 NVIDIA의 CUDA를 직접 지원하지 않는다. 따라서 일반적인 GPU 가속을 위한 PyTorch 바이너리를 사용할 수 없다.2. PyTorch 설치 파일의 종류:CPU 버전: --index-url https://download.pytorch..
딥러닝에서 역전파는 모델을 학습시키는 데 아주 중요한 역할을 한다.마치 학생이 시험을 보고 틀린 문제를 분석하여 다음 시험을 더 잘 보기 위해 공부하는 것처럼, 신경망도 역전파를 통해 자신의 오류를 수정하고 성능을 향상한다. 신경망의 학습 과정신경망의 학습 과정: 신경망은 입력 데이터를 받아 특정 값을 예측하는 모델이다. 이 과정에서 가중치라는 것이 있는데, 이 가중치 값에 따라 예측 결과가 달라진다.오차 발생: 신경망이 예측한 값과 실제 값 사이에는 오차가 발생오차 역전파: 이 오차를 줄이기 위해 신경망은 오차를 역으로 전파하며 각 가중치를 조금씩 수정한다. 즉, 오차에 가장 큰 영향을 미친 가중치를 더 많이 수정하는 방식으로 학습한다.역전파의 과정순전파: 입력 데이터가 신경망을 거쳐 출력 값이 생성되..
 캐글에서 데이터를 가져오기
캐글에서 데이터를 가져오기
위 캡처 데이터를 캐글로부터 가져오는 과정을 기록한다. 내 프로필 > 세팅 > API > create New Token을 누르면 json(유저키)을 받을 수 있다. 우분투에서 작업하기 때문에 home으로 그대로 복사해서 넣어준다.홈에서 캐글 인스톨ubuntu@you:~$ mkdir ~/.kaggleubuntu@you:~$ cp kaggle.json ~/.kaggle/kaggle.jsonubuntu@you:~$ chmod 600 ~/.kaggle/kaggle.json위 명령어 뜻은 다음과 같다.mkdir ~/.kaggle~/.kaggle 디렉토리를 생성. ~는 홈 디렉토리를 나타내므로, 사용자 홈 디렉토리 내에 .kaggle이라는 폴더를 만든다. .kaggle은 숨김 폴더로, 주로 Kaggle API 관련..
from sklearn import linear_model, datasetsimport pandas as pdimport seaborn as snsimport numpy as npfrom matplotlib import pyplot as plt%matplotlib inline# 데이터 불러오기 (California Housing)data = datasets.fetch_california_housing()print(data.keys())print(data.feature_names)print(data.target_names)df = pd.DataFrame(data=data.data, columns=data.feature_names)df['target'] = data.targetdf.head()# 데이터 통계..
1. 회귀란?회귀는 숫자 예측을 할 때 사용하는 방법이다.예를 들어, 집의 크기(입력)를 보고 집값(출력)을 예측하는 것처럼, 숫자를 뽑아내는 문제를 풀 때 회귀를 쓴다. 즉, 회귀 분석은 주어진 입력 데이터(특징)를 바탕으로 연속적인 출력 값을 예측하는 기법으로, 독립 변수와 종속 변수 간의 선형 관계를 가정한다.2. 선형 회귀(Linear Regression)란?선형 회귀는 가장 간단한 회귀 방법이다.데이터를 보고 직선을 그어서, 이 직선을 따라가면서 결과를 예측하는 방식이다.쉽고 기본적이기 때문에 처음에 시도해보기 좋다.데이터를 직선으로 설명할 수 있을 때 잘 맞아떨어진다.(입력과 출력 간의 관계가 선형)다른 모델보다 빠르고 간단해서 처음 학습이 빠르고 과적합(overfitting)의 위험이 적다...
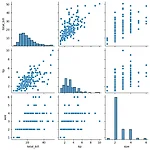 seaborn pairplot를 사용하여 그래프 그려보고 분석하기
seaborn pairplot를 사용하여 그래프 그려보고 분석하기
pip install seaborn import seaborn as snsimport pandas as pdfrom matplotlib import pyplot as plt%matplotlib inline Seaborn 데이터셋 불러오기df = sns.load_dataset('tips')sns.pairplot(df) 1. total_bill의 히스토그램알 수 있는 점: total_bill(계산 금액)의 분포는 오른쪽으로 꼬리가 길게 늘어진 right-skewed 분포. 대부분의 계산 금액은 10에서 20 사이에 집중되어 있지만, 50에 가까운 큰 금액도 몇 건 존재연구자가 주목할 부분: 이상치가 있는지 확인하고, 평균보다 큰 금액의 빈도수에 대한 분석이 필요2. tip과 total_bill 간의 산점..