
- 분류 전체보기 (161)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- ossca
- 으
- R
- inxos
- 메모리인식불량
- 판다스
- nixos한글키보드
- pandas
- 마인크래프트뮤지컬
- 정글사관학교
- 미니프로젝트
- 언리얼뮤지컬
- VUE
- JWT
- 알고풀자
- streamlit
- 오픈소스
- EnhancedInput
- 파이썬서버
- flask
- nixos한글설정\
- 블랙스크린복구
- Bootstrap4
- Express
- 지우개신공 #pc자기진단 #ram미인식 #컴퓨터고장해결 #램인식불량 #pc자가수리 #컴퓨터고장해결 #조립pc
- 디자드
- 스트림릿
- Enhanced Input System
- 프메
- Jinja2
- Today
- Total
Today, I will
[MySQL] 워크밴치에서 Schemas와 Table 만들기 본문

1. Schemas 만들기

Schemas는 데이터베이스의 구분이다. 관련있는 시스템 테이블(엑셀의 표와 같은 역할)끼리 묶어놓은 단위이다. 자바나 노드에서 데이터베이스에 접근을 할 때, 스키마 별로 권한을 줄 수 있다.
ex ) '어떤 자바프로그램(시스템)은 a라는 스키마에만 접근이 가능하다.'
스키마는 한 마디로 생각하면 데이터베이스를 시스템 별로 구분 짓는 것이라고 생각하면 된다. 그리고 스키마 별로 관련있는 테이블들을 관리할 수 있다.


utf8로 설정 : 모든 언어를 다 담을 수 있음
utf8_general_ci

모두 apply 해주면 스키마가 생성된다.

2. 데이타베이스의 Table

어떤 테이블이 먼저 생성되어야 하는지 생각을 하고, 순차적으로 만들어야 한다. 가령, 제품 테이블을 만들기 전에 제품 분류 테이블과 공급처 테이블이 먼저 있어야 한다.

3. Table 만들기

데이터베이스에서 칼럼(Column) 외에도 다양한 용어와 개념이 사용된다.
- 레코드(Record) 또는 행(Row): 데이터베이스 테이블에서 각각의 개별 데이터를 나타내는 단위.
- 기본 키(Primary Key): 레코드 간에 중복이 일어나지 않기 위해 설정. 테이블에서 각 행을 고유하게 식별하는 열(칼럼). 일반적으로 테이블에서 기본 키는 중복되지 않으며, 모든 행에 대해 고유한 값을 가져야 한다. 대표적으로 ID 칼럼이 기본 키로 사용될 수 있다.
- 외래 키(Foreign Key): 테이블 간의 관계를 나타내는 칼럼. 한 테이블의 외래 키는 다른 테이블의 기본 키와 관계를 맺는다. 외래 키를 사용하여 테이블 간의 관계를 설정하고 연결할 수 있다.
- 인덱스(Index): 데이터베이스에서 검색 속도를 향상시키기 위해 생성되는 데이터 구조. 인덱스는 특정 칼럼에 대한 정렬된 데이터 집합으로, 특정 값을 검색하거나 정렬하는 데 사용된다.
- 제약 조건(Constraint): 테이블에 적용되는 규칙 또는 제한 사항. 예를 들어, NULL 값을 허용하지 않도록, 고유한 값만 허용하도록, 특정 범위의 값만 허용하도록 등을 제약 조건으로 설정할 수 있다.
가령

위의 상황에서는 전자기기 행이 겹치는 문제가 발생한다.

반면 위의 상황에서는 사원들의 이름이 겹쳐도 상관없다.

사실 관습적으로 첫번째 칼럼은 pk이다.



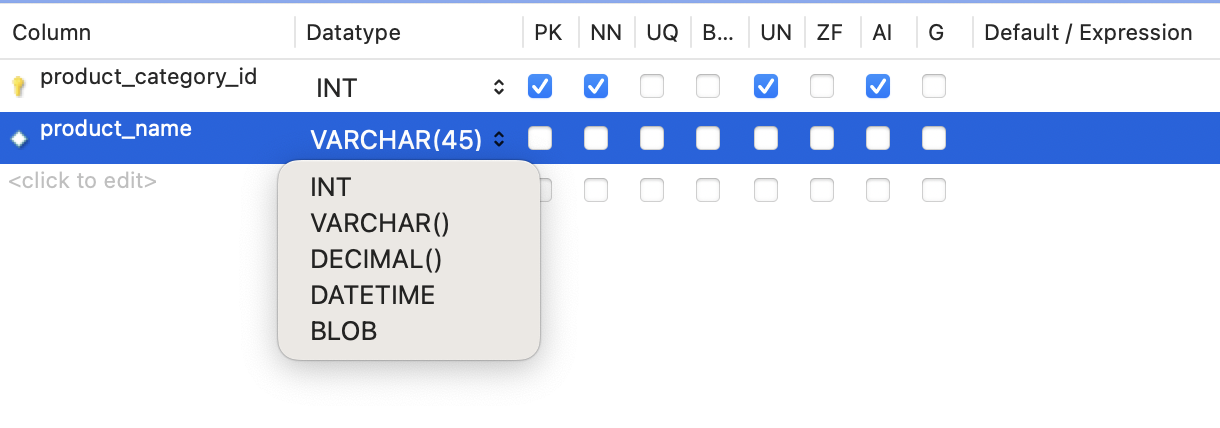

생성 후에 렌치를 누르면 다시 보거나 수정하거나 추가할 수 있다.


가령 node Js가 SELECT * FROM dev.product_category를 실행하면 데이타베이스에서 그 결과값을 받아갈 수 있다. 그러면 서버단은 클라단으로 넘겨주는 작업 등을 할 것이다.
가장 기본적인 데이터를 생성해서 넣고, 데이터를 조회하고, 데이터를 수정하고, 데이터를 삭제하는 것들도 추후에 다 배워야 한다.

공급처가 추가될 때마다, 그 시간과 날짜시분초 등을 기록하고 싶다면 마지막 필드인 created_datetime를 추가하고, Datatype을 DATETIME으로 써준다. 그리고 무조건 들어와야 하므로 NOT NULL, Default에 current_timestamp() 작성
사실 개발자가 레코드를 서버에서 데이타베이스에 넣는 시점에 생성날짜일년원시분초를 넣어줄 수 있지만, 데이터레코드가 추가되는 시점에 데이터베이스가 알아서 그때의 년월일시분초를 자동으로 처리해주면 개발자는 훨씬 편할 것이다.

그리고 누가 레코드를 등록했는지 알고 싶으면, 시스템을 사용하는 userid를 넣을 수도 있다.

< product_supplier 최종 >

4. Pk vs Unique
primary key에 들어오는 값들은 절대 중복되는 값들이 있으면 안된다. 그런데 pk 말고도 unique를 줄 수 있다. 가령, product table에 pk가 따로 잡혀 있어도 시리얼넘버라는 칼럼을 줄 수 있고, 이 시리얼넘버는 레코드마다 단일해야한다. 이럴때 unique를 표시하면 primary key는 아니지만, 단일성을 보장할 수 있다.


제품분류가 product_category_name 같아도 product_category_id 를 넣어주어야 한다.

mysql은 rdb(relational data base)라고 한다.


예전의 dbms는 product_category에 특정 product_category_id가 없는 데도 불구하고, product에 특정 product_category_id를 추가하면 곧이 곧대로 추가가 되었다. 그러나 rdbms는 product_category에 없는 데이터를 갖고 product 테이블에 넣으려고 하면 error를 낸다. 이걸 가능하게 하는 것이 rdb이다. (relation data base)
5. Foreign Keys
foreign key에서 reference table은 연결해줄 테이블이다.
한 테이블의 컬럼이 곧 다른 테이블의 컬럼이라면, 연결을 해주어야 한다. relation database system의 특징이 어떤 테이블에 있는 특정 컬럼이 다른 어떤 테이블에 있는 특정 컬럼하고 똑같은 것라면 시스템적으로 똑같은 것이 맞다고 매핑(연결)해주어야 한다. 그것을 relation 이라고 한다. 그럼 기존에 있는 데이터만 다른 테이블의 컬럼으로 등록할 수 있게 된다. 연결을 Foreign Key로 해야한다.

다시한번 정리하자면, 현재 product 테이블에서의 foreign keys 탭에서 referenced table에서 내가 연결해줄 테이블을 선택해준다. 그리고 현재 테이블에서 어떤 컬럼을 referenced table로 지정한 product_category 테이블의 어떤 컬럼과 연결해줄 것인가를 결정하기 위해 현재 product table의 product_category_id 컬럼을 referenced table인 product_category 테이블의 product_category_id와 연결해주는 것이다.

apply 해주면 색깔이 아래 캡처와 같이 빨간색으로 바뀌었다는 것을 알 수 있다. 이제는 단순히 이름만 똑같은 것이 아니고, 물리적으로 연결되어있는 상태가 되었다. 이제 product를 등록할 때 ref table에 등록된 값 외의 다른 값을 등록하려고 하면, 아무리 화면상에서 개발자가 실수를 해서 다른 값을 등록하려고 아무리 노력해도 relation database system(여기서는 mysql) 자체가 잘못된 접근을 다 막아버리게 된다. 알아서 등록못하게 막아주는 것이 rdb의 특징이라고 할 수 있다.



6. Datatype의 활용
Datatype INT(10)는 10억까지를 나타낼 수 있다. 재고 같은 것들은 10억으로 제한해줄 수 있다.


아니면 이렇게 해줄 수도 있다. ENUM("P", "F")
ENUM("P", "F")으로 하면 P 아니면 F 만 들어올 수 있다.


실무에서는 이렇게 칼럼 12~13개가 문제가 아니고, 20~30개까지도 관리를 한다. 자동차 대기업에서의 프로덕트(자동차) 필드는 50개 이상은 된다.

처음에 배송 업체가 등록이 되어서, 배송을 담당하다가 어느 시점이 되면 배송 업체가 폐업을 한다거나 거래관계를 종료할 수도 있다. 그러다가 다시 거래를 재개할 수도 있다. 그러므로 거래가 안된다고 데이터를 삭제해버리면 문제가 될 수 있다. 그러므로 active_yn이라는 필드를 만들어서 관리하면 좋을 것이다.

7. 지금까지의 예제 테이블
* 사실 created_datetime은 default로 다 들어간다고 보면 된다. 그래야만 레코드가 생성된 시점에 데이터베이스에 기록되기 때문이다. 예제에는 미쳐 다 작성해넣지는 못하였다.
그리고, 레코드를 누가 생성하는지 created_user_id 도 다 들어간다고 보면 된다. 유저테이블이 없어서 생략했을 따름이다.
(1) product_category

(2) product_supplier

(3) product

(4) product_shipper

(4) employee

(5) customer
사용자 행위도 컬럼으로 담아낼 수 있으면 좋다. 행위에 해당하는 데이터들을 테이블로 만들어 기록한다는 것이다. 실제 성공하는 서비스는 사용자의 행위를 데이터로 추척해서 잘 남기고, 그것들을 잘 사용한다. 가령 customer 테이블에서 고객이 (1) 어떤 제품을 봤는지, (2) 몇번 봤는지 (3) 정보를 보고 주문을 했는지 안 했는지, (4) 하루 간격으로 어떤 제품을 조회를 했는지.
일주일 안에 같은 제품을 여러번 클릭했다는 것은 갈등지표이므로, 마케팅으로 최종 구매까지 도달하도록 견인할 수도 있기 때문이다.
사용자들의 어떠한 패턴을 저장하는 테이블을 만들어서 사용자들의 모든 패턴들을 잘 등록해놔야 그것을 활용해서 기획단에서 더 큰 value를 창출하는 것이다.
'Computer Science > 데이터베이스' 카테고리의 다른 글
| [MongoDB] mongodb 세팅과 Compass, 관계형 DB와의 차이점 (0) | 2023.07.17 |
|---|---|
| [MySQL] w3schools 및 MySQL 워크밴치에서 Try mysql (SELECT문, INSERT INTO문, UPDATE문, DELETE문) (0) | 2023.06.04 |

