Computer Science/인공지능,딥러닝
Naive RAG, 라마인덱스 간단 구성
Lv.Forest
2025. 4. 28. 14:32
1. from llama_index.core.settings import Settings
Settings는 RAG 시스템을 돌리기 위한 기본 도구상자 세트
(글 쪼개기, AI모델 연결하기, 글자수 조절하기, 에러관리까지 다 설정할 수 있어!)
from llama_index.core.settings import Settings
아래와 같이 글로벌한 설정이 가능하다.
Settings.
# RAG 파이프라인 글로벌 설정
Settings.embed_model = OpenAIEmbedding(
model="text-embedding-3-small"
)
Settings.llm=OpenAI(model='gpt-3.5-turbo',temperature=0)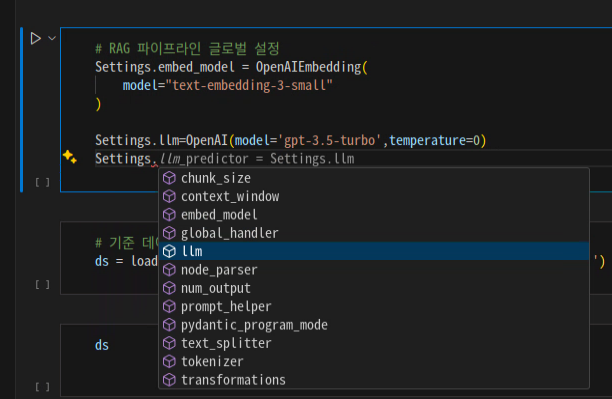
Settings 안에 있는 속성들의 역할 정리
항목 역할
| chunk_size | 텍스트를 "몇 글자 단위"로 쪼갤지 정하는 설정 (예: 긴 글을 500자씩 잘라서 처리) |
| context_window | 모델이 한 번에 읽고 이해할 수 있는 "최대 길이"(너무 길면 잘라야 한다) |
| embed_model | 문장을 숫자 벡터로 바꿔주는 '임베딩 모델'을 지정 (검색이나 유사도 계산용) |
| global_handler | 전체 프로그램에서 에러나 특별한 상황을 다루는 "관리자" 역할(거의 자동 설정) |
| llm | 실제로 텍스트를 생성하거나 답변하는 "AI 모델" 자체를 뜻(ex. gpt-3.5-turbo) |
| node_parser | 글을 쪼개서 "작은 조각"으로 만드는 방법(예: 문단별로 나누기) |
| num_output | LLM이 한 번에 출력할 수 있는 "최대 글자 수" (짧게 vs 길게 답변 설정) |
| prompt_helper | 프롬프트(명령어)를 쓸 때 도와주는 도구(ex. 문장 형식을 예쁘게 맞춰줌) |
| pydantic_program_mode | 코드 검사나 데이터 검사를 편하게 해주는 모드 설정 (프로그램 안정성 강화) |
| text_splitter | 긴 문장을 적당히 "끊어주는 도구"를 고름. (예: 문장 끝에서 자르기) |
| tokenizer | 글자를 AI가 이해할 수 있는 "토큰" 단위로 바꿔주는 도구 (ex. 'hello' → [15496]) |
| transformations | 텍스트를 변형하거나 전처리하는 방법들을 모아둠 (ex. 소문자 변환, 특수문자 삭제) |
굉장히 다양한 설정들을 전역적으로 할 수 있어 상당히 편리하다.
다음에 더 깊게 들어가보고 싶으면,
예를 들면 embed_model이나 tokenizer 안에서 또 어떤 세부 옵션들이 있는지도 들어갈 수 있다.