
- 분류 전체보기 (136)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- R
- 레베카
- 프린세스메이커
- 알고풀자
- 프메
- 언리얼프로그래머
- 카렌
- 정글사관학교
- 으
- 미니프로젝트
- Bootstrap4
- Enhanced Input System
- 언리얼
- Express
- 스터디
- flask
- 스마일게이트
- 파이썬서버
- EnhancedInput
- Unseen
- 게임개발
- node
- Ajax
- VUE
- 언리얼뮤지컬
- Jinja2
- 마인크래프트뮤지컬
- JWT
- 디자드
- 데이터베이스
- Today
- Total
Showing
[CS:APP] 컴퓨터 시스템 Implicit Free Lists 묵시적 가용 리스트 구현 본문
* 본 포스팅은 책 <컴퓨터 시스템>의 말록랩 구현 실습을 위해 책을 요약하고, 더울어서 코드에서 비롯되는 의문점들을 보기 쉽게 정리하기 위한 목적으로 작성되었습니다.
1. 가용 리스트 조작을 위한 기본 상수 및 매크로 정의
가용리스트에서 헤더와 푸터를 조작하는 것은 어려울 수 있는데, 많은 양의 캐스팅과 포인터 연산을 사용해야 하기 때문입니다. 그래서 가용 리스트에 접근하고 방문하는 작은 매크로들을 정의하는 것이 도움이 됩니다.
/* Basic constants and macros */
#define WSIZE 4 /* Word and header/footer size (bytes) */
#define DSIZE 8 /* Double word size (bytes) */
#define CHUNKSIZE (1<<12) /* Extend heap by this amount (bytes) */
#define MAX(x, y) ((x) > (y)? (x) : (y))
/* Pack a size and allocated bit into a word */
#define PACK(size, alloc) ((size) | (alloc))
/* Read and write a word at address p */
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) = (val))
/* Read the size and allocated fields from address p */
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)
/* Given block ptr bp, compute address of its header and footer */
#define HDRP(bp) ((char *)(bp) - WSIZE)
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
/* Given block ptr bp, compute address of next and previous blocks */
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE)))
#define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE)))(1) Basic constants and macros
- WSIZE: word size를 byte 단위로 나타내는 상수
- DSIZE: double word size를 byte 단위로 나타내는 상수
- CHUNKSIZE: 힙을 CHUNKSIZE 바이트 만큼 확장하는 상수.
- MAX(x, y): x와 y 중 더 큰 값을 반환하는 매크로 함수입니다.
- 1- CHUNKSIZE가 2의 12승 (4096)으로 정의된 이유
CHUNKSIZE는 힙(heap)을 확장할 때 추가로 할당하는 메모리의 크기를 바이트 단위로 정의한 매크로입니다. 1<<12는 2의 12승(즉, 4096)을 나타냅니다.
많은 운영 체제에서 페이지 크기는 일반적으로 4KB로 설정되며, CHUNKSIZE가 2의 12승, 즉 4096으로 설정된 것은 페이지 크기와 일치하기 때문입니다.
페이지는 가상 메모리 시스템에서 물리 메모리를 관리하는 단위로 사용됩니다. 페이지 크기는 가상 메모리에서 물리 메모리로 데이터를 전송하는 데에도 사용됩니다. 이렇게 하면 메모리 할당기가 메모리를 할당할 때 페이지 경계를 고려하여 할당할 수 있습니다.
이는 메모리 사용을 최적화하고, 메모리 단편화를 최소화하기 위해 중요합니다.
(2) Pack a size and allocated bit into a word
- PACK(size, alloc): 주어진 블록 헤더 값(크기와 할당 여부)을 하나의 4바이트 워드로 압축하는 역할
가령, "PACK(0, 1)"은 힙의 마지막을 나타내는 "에필로그(epilogue)" 헤더를 만들기 위해 사용됩니다. 이 값은 힙 내에 더 이상 사용 가능한 블록이 없음을 나타내는데, 크기는 0이고 할당 여부는 1(할당되어 있음)입니다.
에필로그 헤더는 힙의 끝을 표시하는 역할을 하며, 할당 블록의 끝을 가리키기 위해 사용됩니다. 따라서 "PACK(0, 1)"으로 압축된 워드가 에필로그 헤더가 되고, 이 값은 힙의 끝에 위치한 4바이트 워드에 저장됩니다.
(3) Read and write a word at address p
- GET(p): 주소 p에서 워드를 읽어 반환하는 매크로 함수
- PUT(p, val): 주소 p에 값을 쓰는 매크로 함수
인자 p가 (void*) 포인터이기 때문에 직접적으로 역참조할 수 없어 (unsigned int)로 형변환해줍니다.
(4) Read the size and allocated fields from address p
- GET_SIZE(p): 블록의 헤더에서 크기 필드를 읽어 반환하는 매크로 함수
- GET_ALLOC(p): 블록의 헤더에서 할당된 비트를 읽어 반환하는 매크로 함수
- 1 - 비트마스크 활용
GET_SIZE(p) 매크로는 GET(p)에서 마지막 3비트(0111)를 비트 마스크로 사용하여, 할당 비트를 제외한 크기 필드를 반환합니다. 크기 필드는 블록 크기를 나타냅니다.
GET_ALLOC(p) 매크로는 GET(p)에서 마지막 비트(0001)를 비트 마스크로 사용하여, 할당 비트를 읽어옵니다. 할당 비트는 해당 블록이 할당되어 있는지 여부를 나타냅니다.
~0x7은 0x7에 대한 비트 반전 (bitwise negation) 연산을 수행한 값입니다.
0x7은 4바이트 워드에서 마지막 3비트를 나타내는 마스크 값이며, ~0x7은 마스크를 반전시켜서 마지막 3비트를 제외한 나머지 비트를 모두 1로 설정한 값을 얻게 됩니다. 즉, GET_SIZE 매크로에서 GET(p)로부터 반환된 워드 값을 받아와서 마지막 3비트를 제외한 나머지 비트를 반환하게 됩니다. 이 비트들은 해당 블록의 크기를 나타내는 비트들입니다.
GET_ALLOC 매크로에서는 워드 값에서 가장 마지막 비트 (least significant bit)를 반환하게 됩니다. 이 비트는 해당 블록이 할당되었는지 여부를 나타내는 비트입니다. 할당되었으면 1, 그렇지 않으면 0이 됩니다.
(5) Given block ptr bp, compute address of its header and footer
- HDRP(bp): 블록 포인터 bp를 인자로 받아 해당 블록의 헤더 주소(헤더를 가리키는 포인터)를 반환하는 매크로 함수
- FTRP(bp): 블록 포인터 bp를 인자로 받아 해당 블록의 푸터 주소(푸터를 가리키는 포인터)를 반환하는 매크로 함수
-1- char *로 형변환하는 이유
"bp"는 "void*" 타입이며, 이것은 어떤 종류의 데이터도 가리킬 수 있는 포인터입니다. 하지만 "HDRP"와 "FTRP"에서는 "bp"를 메모리 블록의 시작점 주소로 가정하고 있습니다. 이를 위해 "bp"가 가리키는 주소에서 WSIZE만큼 빼면 메모리 블록의 시작점에 해당하는 헤더(header)의 주소를 얻을 수 있습니다. 이 주소는 "char*"로 캐스팅되어 있습니다. "FTRP" 함수에서는 헤더에서 메모리 블록의 크기를 가져와서 DSIZE를 빼면 푸터(footer)의 주소를 계산합니다. 푸터 역시 "char*"로 캐스팅되어 있습니다.
이렇게 주소를 캐스팅하는 이유는 C 언어에서 포인터 산술 연산을 위해 포인터가 가리키는 데이터 타입이 정확하게 지정되어야 하기 때문입니다. char *를 사용하는 이유는, malloc 함수가 반환하는 포인터가 byte를 기준으로 메모리를 할당하기 때문입니다. 즉, 반환된 포인터는 메모리의 가장 작은 단위인 byte 단위로 주소가 계산됩니다. 이때, char 타입은 byte 단위로 값을 저장할 수 있기 때문에, 메모리의 주소 값을 저장하기에 적합합니다.
int *를 사용할 수도 있지만, int는 4바이트로 메모리를 할당하므로 byte를 기준으로 메모리를 관리하기에는 적합하지 않습니다. 따라서 char *을 사용하는 것이 좋습니다.
(6) Given block ptr bp, compute address of next and previous blocks
- NEXT_BLKP(bp): 블록 포인터 bp를 인자로 받아 해당 블록 다음 블록의 주소(다음블록의 포인터) 반환하는 매크로 함수
- PREV_BLKP(bp): 블록 포인터 bp를 인자로 받아 해당블록이전블록의주소(이전블록의 포인터) 반환하는 매크로 함수
이러한 매크로들은 가용 리스트를 조작하기 위해서 여러 가지 방법으로 구성할 수 있습니다. 예를 들어, 현재 블록의 포인터 bp가 주어지면, 다음과 같은 코드를 사용해서 메모리 내 다음 블록의 크기를 결정할 수 있습니다.
size_t size = GET_SIZE(HDRP(NEXT_BLKP(bp)));
2. Creating the Initial Free List
(1) int mm_init(void)
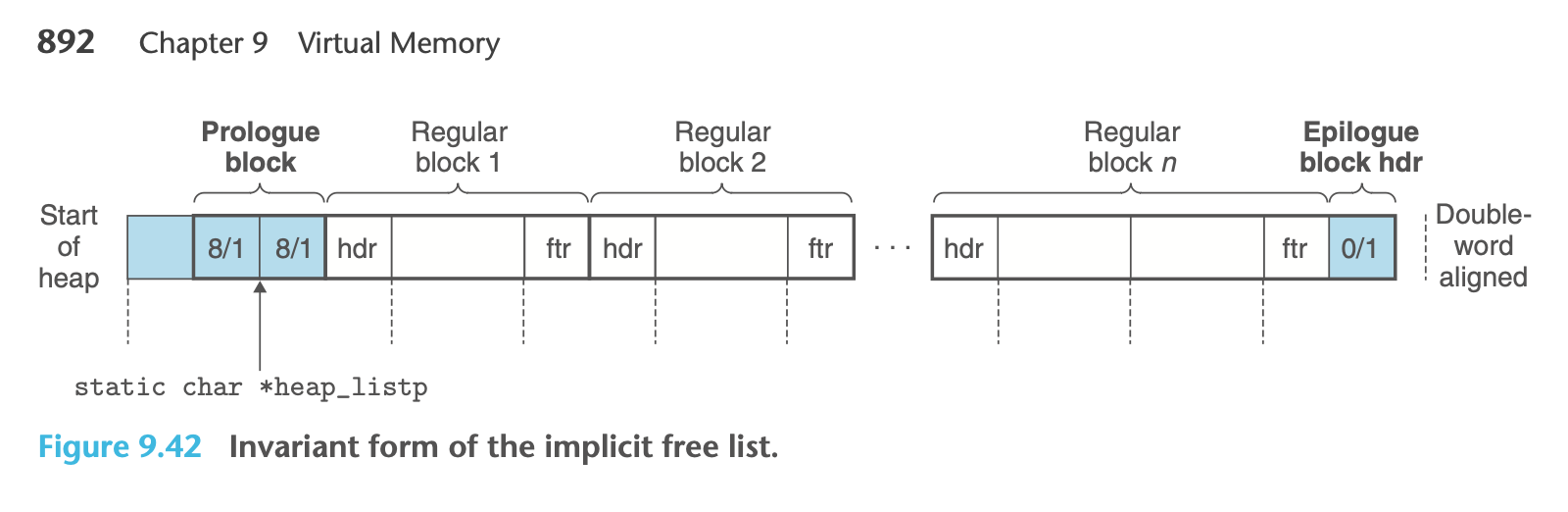
int mm_init(void)
{
// - (void *)-1의 의미 일부 함수는 오류 발생 시 NULL 대신에 (void *)-1을 반환
//[1]
if ((heap_listp = mem_sbrk(4*WSIZE)) == (void *)-1){
return -1;
}
//[2]
PUT(heap_listp, 0); //정렬을 위한 패딩
//[3]
PUT(heap_listp + (1*WSIZE), PACK(DSIZE, 1));
//[4]
PUT(heap_listp + (2*WSIZE), PACK(DSIZE, 1));
//[5]
PUT(heap_listp + (3*WSIZE), PACK(0, 1));
//[6]
heap_listp += (2*WSIZE);
//[7]
if (extend_heap(CHUNKSIZE/WSIZE) == NULL){
return -1;
}
return 0;
}
[1] 예외 반환
if ((heap_listp = mem_sbrk(4*WSIZE)) == (void *)-1){
return -1;
}"(void *)-1"은 포인터 타입으로, 주소값을 나타냅니다. 이 값은 일반적으로 메모리 할당과 관련된 함수들에서 오류 발생 시 반환되는 값입니다.
C언어에서 NULL은 포인터 상수 0으로 정의되어 있으므로, 포인터와 비교할 때 명시적인 형변환 없이도 비교가 가능합니다. 그러나 일부 함수는 오류 발생 시 NULL 대신에 (void *)-1을 반환하므로, 이 경우에는 포인터를 명시적으로 형변환하여 비교해야 합니다.
[2] Unused 설정 PUT(heap_listp, 0);
"PUT"은 매크로 함수로, 주어진 주소에 4바이트(한 워드) 크기의 값을 저장하므로,
여기서 "heap_listp"는 현재 힙의 시작 주소를 가리키는 변수로 "PUT(heap_listp, 0)"은 힙의 시작 주소에 4바이트 크기의 0 값을 저장하는 것입니다.
이 코드는 힙의 가장 처음에 정렬을 위해 필요한 8바이트(프롤로그 헤더와 프롤로그 푸터)를 할당하고, 이를 초기화하기 위해 각각에 0값을 저장하는 작업을 수행합니다. 이를 통해 힙 내의 블록들이 올바르게 정렬되도록 하고, 블록의 크기와 할당 여부를 판별하는데 사용됩니다.
[3] PUT(heap_listp + (1*WSIZE), PACK(DSIZE, 1));
"heap_listp + (1*WSIZE)"은 힙 내에서 두 번째 워드의 주소를 나타냅니다.
"PACK(DSIZE, 1)"은 8바이트(프롤로그 헤더와 프롤로그 푸터) 크기의 블록 헤더 값을 압축한 4바이트 워드를 나타냅니다. 이 값은 프롤로그 헤더를 초기화하기 위해 사용됩니다.
따라서 "PUT(heap_listp + (1*WSIZE), PACK(DSIZE, 1))"은 힙 내에서 두 번째 워드의 주소에 8바이트 크기의 블록 헤더 값을 저장하는 것입니다. 이 블록 헤더는 프롤로그 헤더이며, 블록의 크기가 "DSIZE"이고 할당 여부가 1(할당되어 있음)입니다.
프롤로그 블록은 힙의 시작 부분에 위치하며, 프로그램에서 할당할 수 없는 특수한 블록으로, 힙 메모리 관리를 위한 정보를 저장하는 역할을 합니다. 프롤로그 헤더와 프롤로그 푸터는 서로 동일한 값을 가지며, 이 값은 블록 크기(DSIZE)와 할당 여부(1)를 포함합니다.
[4] PUT(heap_listp + (2*WSIZE), PACK(DSIZE, 1));
"heap_listp + (2*WSIZE)"은 힙 내에서 세 번째 워드의 주소를 나타냅니다.
역시 "PACK(DSIZE, 1)"은 8바이트(프롤로그 헤더와 프롤로그 푸터) 크기의 블록 헤더 값을 압축한 4바이트 워드를 나타냅니다. 이 값은 프롤로그 푸터를 초기화하기 위해 사용됩니다.
따라서 "PUT(heap_listp + (2*WSIZE), PACK(DSIZE, 1))"은 힙 내에서 세 번째 워드의 주소에 8바이트 크기의 블록 헤더 값을 저장하는 것입니다. 이 블록 헤더는 프롤로그 푸터이며, 블록의 크기가 "DSIZE"이고 할당 여부가 1(할당되어 있음)입니다.
[5] PUT(heap_listp + (3*WSIZE), PACK(0, 1));
"heap_listp + (3*WSIZE)"은 힙 내에서 네 번째 워드의 주소를 나타냅니다.
"PACK(0, 1)"은 8바이트(에필로그 헤더) 크기의 블록 헤더 값을 압축한 4바이트 워드를 나타냅니다. 에필로그 헤더를 초기화하기 위해 사용됩니다. 블록 크기를 0으로 설정하면 이 블록은 힙의 끝을 나타내는 에필로그 블록이 됩니다.
"PUT(heap_listp + (3*WSIZE), PACK(0, 1))"은 힙 내에서 네 번째 워드의 주소에 8바이트 크기의 블록 헤더 값을 저장하는 것입니다. 이 블록 헤더는 에필로그 헤더이며, 블록의 크기가 0(에필로그 블록)이고 할당 여부가 1(할당되어 있음)입니다.
[6] heap_listp += (2*WSIZE);
heap_listp += (2*WSIZE) 코드는 프롤로그 블록의 끝 부분(프롤로그 푸터)을 가리키도록 heap_listp를 업데이트합니다.
[7] extend_heap 함수를 호출하여 첫 번째 블록 이후에 새로운 블록을 추가
extend_heap 함수를 호출하여 새로운 블록을 할당하면 첫 번째 블록은 이어지는 프리 블록 리스트의 머리에 추가됩니다. 즉, heap_listp는 이어지는 프리 블록 리스트의 머리를 가리키게 됩니다.
if (extend_heap(CHUNKSIZE/WSIZE) == NULL){
return -1;
}extend_heap 함수를 호출하여 힙에 추가적인 블록을 할당합니다. extend_heap 함수는 주어진 크기 (CHUNKSIZE/WSIZE) 만큼 힙을 확장하고, 새로운 블록을 할당하여 프리 리스트에 추가합니다. 만약 extend_heap 함수가 실패하여 NULL을 반환하면, 함수는 -1을 반환하여 오류를 나타냅니다. 이 경우, mm_init 함수는 초기화에 실패한 것으로 간주됩니다.
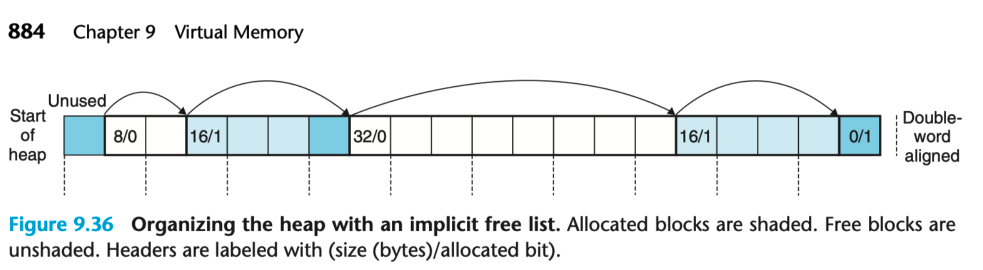
(2) static void *extend_heap(size_t words)
힙을 CHUNKSIZE 바이트로 확장하고 초기 가용 블록을 생성합니다.
static void *extend_heap(size_t words) {
char *bp;
size_t size;
//[1]
size = (words % 2) ? (words+1) * WSIZE : words * WSIZE;
//[2]
if ((long)(bp = mem_sbrk(size)) == -1){
return NULL;
}
//[3]
PUT(HDRP(bp), PACK(size, 0)); /* Free block header */
//[4]
PUT(FTRP(bp), PACK(size, 0)); /* Free block footer */
//[5]
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); /* New epilogue header */
//[6]
return coalesce(bp);
}[1] size 변수 계산
- words를 WSIZE (워드 크기)로 곱한 값을 size에 저장합니다.
- 만약 words가 홀수라면, size에 1을 더해줍니다. (이는 앞서 구현된 메모리 할당 시, 8바이트 단위로 정렬하기 위한 것입니다.)
[2] mem_sbrk를 통한 메모리 확장
//[1]
if ((long)(bp = mem_sbrk(size)) == -1){
return NULL;
}mem_sbrk 함수를 호출하여 size 바이트 크기의 메모리를 할당하고, 그 시작 주소를 bp 포인터에 저장합니다.
만약 메모리 할당에 실패하면, NULL을 반환합니다.
[3] & [4]
PUT(HDRP(bp), PACK(size, 0)); /* Free block header */
PUT(FTRP(bp), PACK(size, 0));/* Free block footer */할당한 메모리에 헤더와 푸터 설정
PUT(HDRP(bp), PACK(size, 0)): bp가 가리키는 블록의 헤더에 size와 0을 패킹하여 설정합니다.
PUT(FTRP(bp), PACK(size, 0)): bp가 가리키는 블록의 푸터에도 동일하게 size와 0을 패킹하여 설정합니다.
[5] PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); /* New epilogue header */
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)) 코드는 새롭게 할당한 메모리 블록 바로 뒤에 있는 가상의 블록(에필로그 블록)에 대한 헤더를 설정하는 코드입니다.
HDRP(NEXT_BLKP(bp)): bp가 가리키는 블록 다음 블록의 헤더 주소를 계산합니다.
PACK(0, 1): 0과 1을 패킹하여 하나의 워드로 만듭니다. 0은 해당 블록의 크기가 0이라는 의미를 가지며, 이는 에필로그 블록이라는 것을 나타냅니다. 1은 해당 블록이 사용 중임을 나타내는 태그(tag)로, 해당 블록이 할당된 것으로 표시합니다.
PUT: 주어진 포인터와 값으로 메모리를 쓰는 매크로로, HDRP(NEXT_BLKP(bp))가 가리키는 메모리 위치에 PACK(0, 1)로 패킹한 값을 씁니다.
따라서, 새롭게 할당한 블록 바로 뒤에 에필로그 블록을 추가하고, 이 에필로그 블록을 사용 중으로 설정하여 할당된 블록의 끝을 표시합니다. 이를 통해 coalesce 함수가 연속된 빈 블록을 결합할 때 블록의 끝을 쉽게 확인할 수 있습니다.
[6] return coalesce(bp);
(3) static void *coalesce(void *bp)
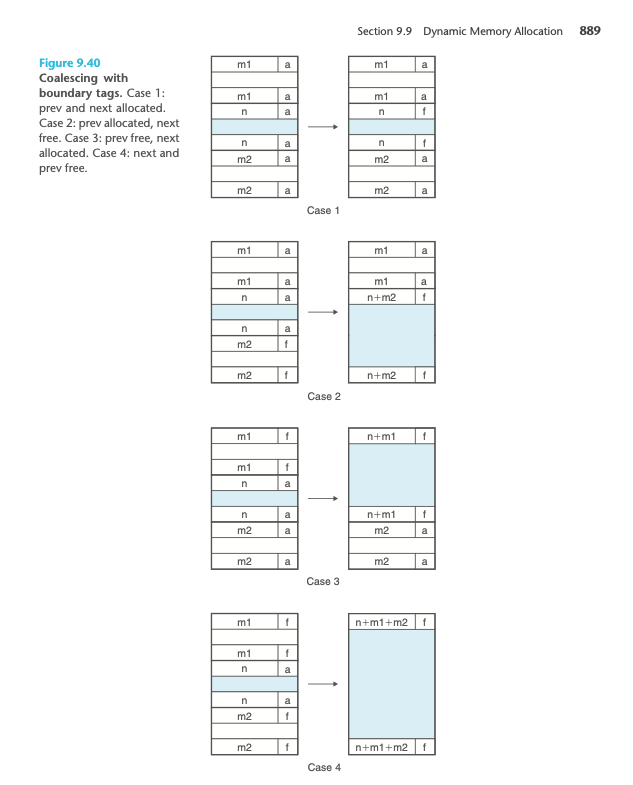
static void *coalesce(void *bp) {
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp));
if (prev_alloc && next_alloc) { // case 1
return bp;
} else if (prev_alloc && !next_alloc) { // case 2
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
} else if (!prev_alloc && next_alloc) { // case 3
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
} else { // case 4
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
return bp;
}
'컴퓨터 공학, 전산학 > 컴퓨터시스템' 카테고리의 다른 글
| [CS:APP] Explicit Free Lists 구현 (0) | 2023.04.11 |
|---|---|
| [CS:APP] 컴퓨터 시스템 9.9 동적 메모리 할당 (0) | 2023.04.07 |
| [CS:APP] 컴퓨터 시스템 3장(1) : 어셈블리어 기초와 gcc, gnu, gdb (0) | 2023.03.27 |
| [CS:APP] 컴퓨터 시스템 1장 : 프로세스 실행과 종료 관점에서 프로세서와 운영체제 역할 차이점 정리 (0) | 2023.03.21 |



